# Grammar
# Architecture
# Concurrency Control
# Read/Write Locks
# Lock Granularity
Table Lock
Row Lock
# Transactions
# Isolation Levels
- READ UNCOMMITTED | Dirty Read
- READ COMMITTED | No Repeatable Read
- REPEATABLE READ | Phantom Read
- SERIALIZABLE | Locking Reads
# Deadlocks
# Transaction Logging
Undo Log
Redo Log
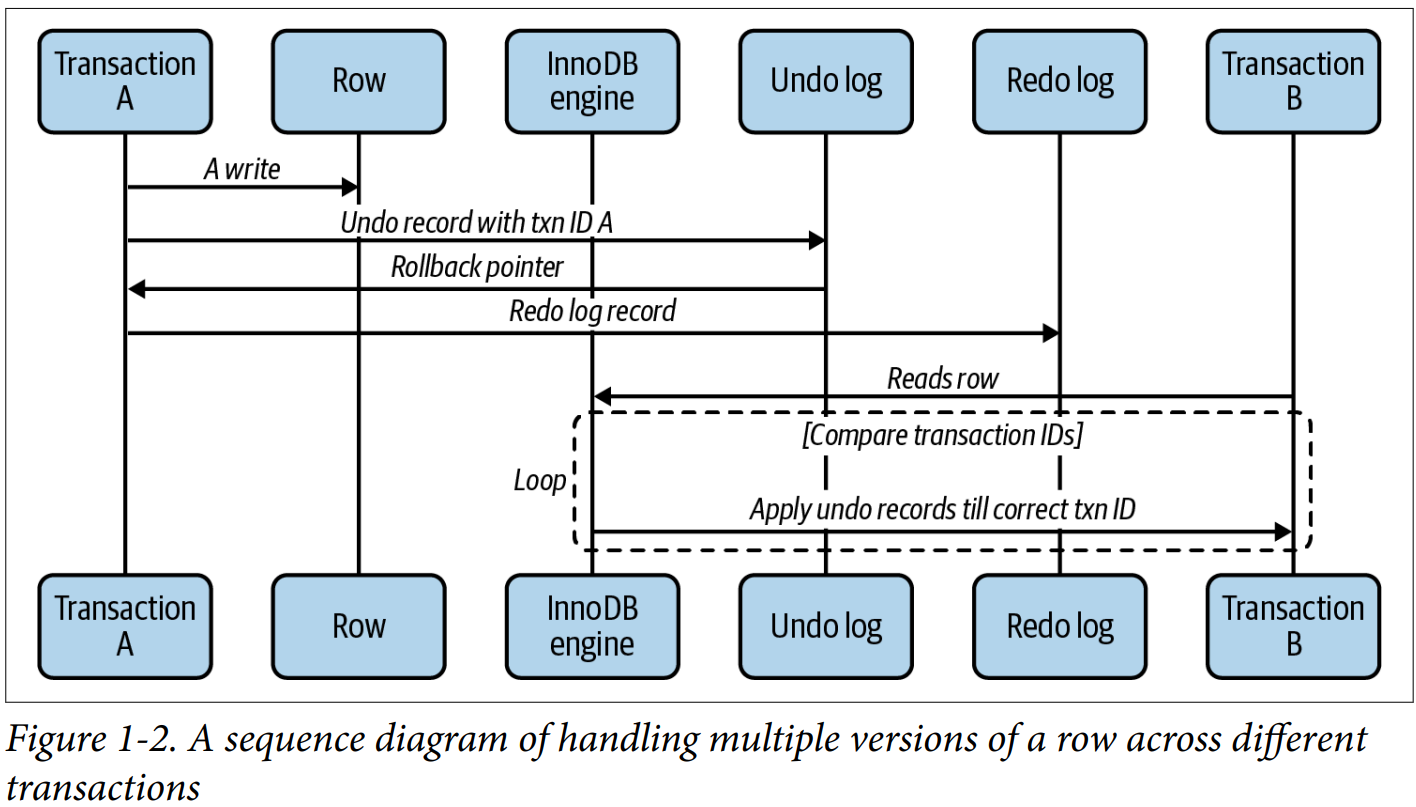
# MVCC
Multiversion Concurrency Control
Transaction ID
Undo record
Rollback Pointer
# Lock
InnoDB solves phantom read under REPEATABLE READ using the lock of gaps in the index structures
锁分类
锁思想
- 悲观锁
- 乐观锁
兼容性 - 共享锁
- 排它锁
实现 - 意向锁(Intention Locks)
- 记录锁(Record Locks)
- 间隙锁(Gap Locks)
- 临键锁(Next-Key Locks)
- 插入意向锁(Insert Intention Locks)
- 自增锁(AUTO-INC Locks)
1 | |
Shared Lock
SELECT * FROM test WHERE id = 1 LOCK IN SHARE MODE;
- 多个事务的查询语句可以共用一把共享锁;
- 如果只有一个事务拿到了共享锁,则该事务可以对数据进行 UPDATE DETELE 等操作;
- 如果有多个事务拿到了共享锁,则所有事务都不能对数据进行 UPDATE DETELE 等操作。
Exclusive Lock
SELECT * FROM test WHERE id = 1 FOR UPDATE;
- 只有一个事务能获取该数据的排它锁;
- 一旦有一个事务获取了该数据的排它锁之后,其余事务对于该数据的操作将会被阻塞,直至锁释放。
Intention Locks
记录锁、间隙锁、临键锁都是排它锁
Record Lock(Row Lock)
SELECT * FROM test WHERE id=1 FOR UPDATE;
Gap Lock
产生间隙锁的条件(RR事务隔离级别下):
- 使用普通索引锁定;
- 使用多列唯一索引;
- 使用唯一索引锁定多行记录。
对于使用唯一索引来搜索并给某一行记录加锁的语句,不会产生间隙锁。(这不包括搜索条件仅包括多列唯一索引的一些列的情况;在这种情况下,会产生间隙锁)例如,如果id列具有唯一索引,则下面的语句仅对具有id值100的行使用记录锁,并不会产生间隙锁。
对于指定查询某一条记录的加锁语句,如果该记录不存在,会产生记录锁和间隙锁,如果记录存在,则只会产生记录锁,如:WHERE id = 5 FOR UPDATE;
对于查找某一范围内的查询语句,会产生间隙锁,如:WHERE id BETWEEN 5 AND 7 FOR UPDATE;
在普通索引列上,不管是何种查询,只要加锁,都会产生间隙锁,这跟唯一索引不一样;
在普通索引跟唯一索引中,数据间隙的分析,数据行是优先根据普通索引排序,再根据唯一索引排序。
Next-Key Locks
临键锁,是记录锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。
注:临键锁的主要目的,也是为了避免幻读(Phantom Read)。如果把事务的隔离级别降级为RC,临键锁则也会失效。
Insert Intention Locks
AUTO-INC Locks
表级锁
如果将三条查询语句放到同一事务中,在RR事务隔离级别下,是不会出现这种情况的,因为RR事务隔离级别,会解决幻读现象。
自增锁不仅是只对 INSERT INTO 语句才会出现,还对其它的插入语句生效。
自增锁幻读
Predicate Locks for Spatial Indexes
传统模式(Traditional)
连续模式(Consecutive)
交叉模式(Interleaved)
可能你还没看出问题在哪儿,INSERT 同时交叉执行,并且 AUTO_INCREMENT 交叉分配将会直接导致主从之间同行的数据主键 ID 不同。而这对主从同步来说是灾难性的。
换句话说,如果你的 DB 有主从同步,并且 Binlog 存储格式为 Statement,那么不要将 InnoDB 自增锁模式设置为交叉模式,会有问题。其实主从同步的过程远比上图中的复杂,之前我也写过详细的MySQL主从同步的文章,感兴趣可以先去看看。
如果你可以断定你的系统后续不会使用 Binlog,那么你可以选择将自增锁的锁模式从连续模式改为交叉模式,这样可以提高 MySQL 的并发。并且,没有了主从同步,INSERT 语句在从库乱序执行导致的 AUTO_INCREMENT 值不匹配的问题也就自然不会遇到了。
# Replication
Binary Log
# Performance Schema
# OS & Hardware Optimization
# CPU
Low latency (fast response time)
To achieve this, you need fast CPUs because each query will use only a single CPU.
High throughput
If you can run many queries at the same time, you might benefit from multiple CPUs to service the queries.
# Cache
Many writes, one flush
A single piece of data can be changed many times in memory without all of the new values being written to disk. When the data is eventually flushed to disk, all the modifications that happened since the last physical write are permanent. For example, many statements could update an in-memory counter. If the counter is incremented one hundred times and then written to disk, one hundred modifications have been grouped into one write.
I/O merging
Many different pieces of data can be modified in memory, and the modifications can be collected together, so the physical writes can be performed as a single disk operation.
write-ahead log sequential I/O
# Indexing
# Query Optimization
# Scaling
# Concurrency
# Availability