Resumes.
# TODO
TVM
ONNX Runtime
ffmpeg
# Outline
- Business background
- Solution
- Implementation
- Result (explained with data)
- Problem/Bad case
- Optimization
# Backend Developer Engineer
Mainly focus on the backend system design, middleware (MySQL/Postgres, Redis, Kafka, MongoDB) and Golang & Python.
# Experience
Alibaba Group 2018/07 – Present Senior Development Engineer PAI Computing Platform of Alibaba Cloud
- Lead the design and development of specific industry products, including the generalized recommendation engine, the marketing growth platform, the video enhancement platform.
- Participate in the development of optimized inference optimization toolkits integrated with machine learning products, including vendor solutions, community solutions, and self-developed FPGA acceleration chip solutions.
# 后端开发工程师
# 工作经历
高级开发工程师 2020-present
AI Model/Go/Devops
# Video Enhancement
负责人与主程。视频增强效果指标与友商基本持平,单位视频时间转换成本较友商公开数据低50%以上。效果层面,基于SISR模型,通过扩充训练集加入人像、字符、纹理与业务场景数据,混合多种Loss与退化方法fine-tune,适配业务需求,做到保留高频细节、降噪、避免artifact。通过压缩量化等方法提升推理性能,维持主观效果基本持平;基于K8S部署多个Go微服务,包括API、任务调度、状态同步、回调等服务,使用Kafka做任务队列,Python编写模型推理与ffmpeg编码Worker,使用ECS扩缩容节省资源,使用ECI扩容支持突发流量,Redis实现公共与用户专用任务队列,使用Kafka同步状态消息。处理时间比要求高的任务,使用视频分块处理提高处理时间比。
The subjective evaluation results are better than other vendors or at least on par, and the cost per minute of conversion is more than 50% lower than the price of other vendors. We chose SISR model, expanded the specific image set for training, mixed a variety of loss functions and degradation methods, so as to preserve high-frequency details, reduce noise, and avoid artifacts. The inference performance is improved through compression and quantization while keeping accuracy. Go microservices are deployed in K8S, including API Server, task scheduler, state synchronizer, callback and monitor services. Workers for model inference and FFmpeg encoding are developed in Python, and scaled with ECS to save costs, and with ECI to handle the burst traffic. Redis is used for task queues, and Kafka is used to synchronize state messages. For tasks require low processing time, videos are split into chunks for parallel processing.
-
Why are you doing this? What’s it for? Are there any competitors in the market? Think in a higher level of business.
为什么做?业务背景是什么?有什么收益?效果?有什么技术难度?怎么克服的?有技术深度吗?
Why and how that could achieve?
We start from a real business requirement: save the bandwidth but provide the similar quality. And how could achieve that, two of the possible solutions in front us: one is that improve the h265 encoding quality of ffmpeg, which is way too professional for us with a machine learning background, the other is that send the video with low quality and restore the video quality back on client side.
Here, the low quality refers to 2 aspects: resolution and bitrate.
For the former aspect, the technology called super resolution (SR for short) has been widely researched in academia of deep learning. SR models are used to generate high resolution images from low resolution images. And during our research, we found that two-step processing involves model enhancement and ffmpeg encoding on the server side is also a possible solution for video enhancement.
So I start to lead the solution from the server-side. The challenges that I will encounter are how to improve the subjective assessment score of the model as much as possible because on the cloud, we have a way larger space and powerful GPU than the client side, and avoid the artifacts introduced by the model, how to improve the performance and save costs by compressing the model. And how to deploy a scale worker pool and keep track of jobs.
For the other solution, they are facing with the challenges of how to compress the model as much as possible in order to run it on mobile phone without causing excessive heat and consuming too much power.What is the business opportunity?
We compared our results with other competitors and found that most of them are just using a simple preprocessing or even have no preprocessing. And the visual quality of our results are obviously better than theirs even under a lower bitrate.
But here’s a lot of tricky things. Most of the company want to try and buy, even they had seen the visible improvement. They want free A/B Test.The cost. If we just have better visual quality, most of companies do not have strong motivations to transfer their systems, because the work to develop and test the new system is relatively considerable.
So another strong reason is the cost, the cost of transcoding, the cost of CDN etc.How could you solve that?
How could you cut the cost.All procedures are verified through AB Testing.
The commonly object metrics like SNR are not aligned with the visible quality. And because we don’t a true reference video, the full-reference metric like VMAF cannot be used. Because the original video quality is not that good, what we do here is to improve the quality of the original video. So we take subject visual assessment as a important method. But due the preferences of different flavors of the customers, we are often compared with the competitor’s videos together using a group of standard reference videos picked by the customers from their video libraries. and let the customer decide. We are welcome if the customers give us the feedbacks of what kind of the style they want, like is the video too sharp, too bright, or the video needs more retouch on human face or needs. Sometimes, they just describe the feelings of what they want and we will slightly change the hyperparameter and fine-tune a model for them. But this is only for the
Here we make a assumption that the audiences from different video platforms may have different preferences on the video style. For example, audiences from some video apps like a heavily retouching effect on human faces, the audience from another video apps may want a video full of sharpened details or edges.
-
架构
支持视频增强模板或动态传入参数,任务调度服务查询新增任务并置于任务队列,worker pool中worker读取,node manager管理节点和worker,部署在ACK(AliCloud Container Service for Kubernetes)/AWS EKS(Elastic Kubernetes Service)使用ECI(Elastic Container Instance)/AWS Fargate扩容应对突发流量,使用ECS(Elastic Compute Service)/AWS EC2(Elastic Compute Cloud)作为常驻worker。用户默认共享public pipeline,public pipeline使用公用worker pool,每个用户提交的任务round robin进入task queue。如果对处理实时性有要求,可以申请私有pipeline,私有pipeline有独立的worker pool,处理的速度与用户设定的worker pool size指定的机器规格有关。任务处理中,在特殊的节点,worker写回状态消息队列,当任务处理完成或出错后,worker写回结果消息队列。状态同步服务读取状态并批量合并处理同步到数据库中,进度信息将会反应在前端页面或API查询结果中。结果服务批量同步处理结果到数据库。用户回调服务读取任务状态并回调。任务调度服务的功能还包括,根据失败原因对失败的任务重试,监测超时的任务并重试(worker意外关闭,被驱逐,node错误下线)。
优化:
专业用户希望提高,为提高处理时间比,切分视频块,视频块关联子任务。对于分块任务,分块服务根据固定策略切分子任务,写入子任务数据库,同时提交分块任务到分块队列,分块任务将分块后的视频上传至OSS(Object Storage Service)/S3(Simple Storage Service)。子任务数据库由任务调度服务调度并处理。合并服务定期查询子任务完成状况,当所有子任务都完成后,提交merge任务。
-
扩容策略是什么?怎么区分突发流量?
监控平均利用率,超过一定比例后,拉起ECS的常驻Worker。
排队数量快速增长,使用ECI拉起一次性Worker,一次性Worker执行N个任务后自动退出。
-
怎么发布新版本?怎么做灰度测试?
我们有三个环境,日常,Daily,预发,PreLaunch,生产,Production
Rolling Update for Daily and preLaunch
Blue Green Release for ProductionHelm创建多个指向同一个Service的Deployment。
-
怎么切流?做蓝绿发布?
创建旧service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36apiVersion: apps/v1
kind: Deployment
metadata:
name: old-nginx
spec:
replicas: 2
selector:
matchLabels:
run: old-nginx
template:
metadata:
labels:
run: old-nginx
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/acs-sample/old-nginx
imagePullPolicy: Always
name: old-nginx
ports:
- containerPort: 80
protocol: TCP
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: old-nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: old-nginx
sessionAffinity: None
type: NodePort创建旧ingress
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gray-release
spec:
rules:
- host: www.example.com
http:
paths:
# 老版本服务。
- path: /
backend:
service:
name: old-nginx
port:
number: 80
pathType: ImplementationSpecific创建新service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36apiVersion: apps/v1
kind: Deployment
metadata:
name: new-nginx
spec:
replicas: 1
selector:
matchLabels:
run: new-nginx
template:
metadata:
labels:
run: new-nginx
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/acs-sample/new-nginx
imagePullPolicy: Always
name: new-nginx
ports:
- containerPort: 80
protocol: TCP
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: new-nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: new-nginx
sessionAffinity: None
type: NodePort创建新ingress按请求头路由
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gray-release-canary
annotations:
# 开启Canary。
nginx.ingress.kubernetes.io/canary: "true"
# 请求头为foo。
nginx.ingress.kubernetes.io/canary-by-header: "foo"
# 请求头foo的值为bar时,请求才会被路由到新版本服务new-nginx中。
nginx.ingress.kubernetes.io/canary-by-header-value: "bar"
spec:
rules:
- host: www.example.com
http:
paths:
# 新版本服务。
- path: /
backend:
service:
name: new-nginx
port:
number: 80
pathType: ImplementationSpecific按流量路由
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gray-release-canary
annotations:
# 开启Canary。
nginx.ingress.kubernetes.io/canary: "true"
# 请求头为foo。
nginx.ingress.kubernetes.io/canary-by-header: "foo"
# 请求头foo的值为bar时,请求才会被路由到新版本服务new-nginx中。
nginx.ingress.kubernetes.io/canary-by-header-value: "bar"
# 在满足上述匹配规则的基础上仅允许50%的流量会被路由到新版本服务new-nginx中。
nginx.ingress.kubernetes.io/canary-weight: "50"
spec:
rules:
- host: www.example.com
http:
paths:
# 新版本服务。
- path: /
backend:
service:
name: new-nginx
port:
number: 80
pathType: ImplementationSpecific修改旧版本Service,使其指向新版本服务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14apiVersion: v1
kind: Service
metadata:
name: old-nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
# 指向新版本服务。
run: new-nginx
sessionAffinity: None
type: NodePort等完全切流后
删除旧版Deployment,删除新版Service
-
金丝雀发布是什么?
-
滚动发布的优缺点?
-
Partition数量 < Consumer数量会发生什么?怎么处理?
超出数量的Consumer将不工作。增加partition数量,保证partition > consumer。
-
partiton分区数量可以无限大吗?为什么?有什么问题?
不行,数量过多之后严重影响系统性能。Tech部分有介绍。
-
如果改用worker读数据库并结合分布式锁会有什么问题?
数据库连接数不够。
-
如果Redis突然失效了任务丢了怎么办?
有任务超时兜底。根据任务视频预估处理时间,在阈值内超时重试。
-
Redis任务队列怎么实现的?
使用List,RPUSH Task Json,BLPOP获取。定义优先级队列。BLPOP default0, default1, default2 … TIMEOUT
- AOF flush to disks more often, ack?
- Timed Out?
-
RabbitMQ任务队列?
- Message acknowledgment
Delivery Acknowledgement Timeout1
ch.basic_ack(delivery_tag = method.delivery_tag) - Message durability
1
2
3
4
5
6
7channel.queue_declare(queue='hello', durable=True)
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = pika.spec.PERSISTENT_DELIVERY_MODE
)) - Publisher Confirms
1
2channel.confirm_delivery(ack_nack_callback, callback=None)
channel.basicPublish(exchange, queue, properties, body) - Fair dispatch
channel.basic_qos(prefetch_count=1) - Get the status
1
name, jobs, consumers = chan.queue_declare(queue=queuename, passive=True)
- Message acknowledgment
-
讲讲RabbitMQ基本原理?
-
配置更新?
configmap
- 初始设计
最早使用任务调度直接创建Job的形式。面临的问题是:- 调用K8S同步创建Job的开销很大,每次创建需要很久,开始是每个任务创建一个namespace并分配资源,job启动的速率非常低,后改为批量启动job共享资源,异步创建缓解。
- Job存在启动开销,对于常驻Job,启动时间可以忽略不计,但是对于弹性Job,最短也需要十几秒的启动时间,
- Job状态同步直写数据库连接数不足,后改为通过内部API返回数据,API调用加重试,服务使用channel缓存并批量处理。在上千Job同时运行时,请求量较大,出现状态丢失的情况。
# 营销增长平台
负责人与主程。平台提供短信和算法服务,采用后付费方式与阿里云计费接口对接。短信服务使用Hologres数据库和Kafka支持每日亿级短信记录以及上千QPS输入(最高100条短信/query),通过分区表归档历史短信记录缓解查询压力。算法层面支持通用数据传输协议,基于客户提供的数据质量,采用通用分类模型,目标效果有不同程度的提升。基于K8S部署多个Go微服务,包括API,短信的发送、重发、运营商回执校验,发送统计,定时分区,用户回执推送,实时短信quota消耗计量,周期短信任务,算法任务,监控警报服务等。
The platform provides SMS and algorithm services, and connects with Alibaba Cloud’s billing system in a post-paid manner. The SMS service uses the Hologres database and Kafka to support hundreds of millions of messages per day and thousands of input request per second (up to 100 messages/requests), and the service archives historical messages as partitions to ease the query pressure. The algorithm service supports general data transmission protocols and provides general prediction models tuned for different scenarios. Based on the data quality provided by customers, the target indicator of customers can be improved to varying degrees. Go microservices are deployed in K8S, including API, message sender, resender, vendor receipt verifier, metrics, timed partitioning, user receipt pusher, quota measurer, periodic sending tasks, algorithm tasks, and monitor services.
-
为什么做?业务背景是什么?有什么收益?效果?有什么技术难度?怎么克服的?有技术深度吗?
Application for non-machine learning company. Traditional marketing & growth platforms provide the ability to manage user, select user according to the user features, send messages via different channels including SMS, App Push, Email etc.
More and more small and medium-sized companies are adopting data-driven operational strategies. The operations specialists plan marketing campaign by analyzing the collected feedback data using SQL.
What we want do is using machine learning models to predict target indicators and standardizing and automating the whole process. That would be provide data format to customers, send messages to users, get feedback data (we have a partner provides tracking sdks), train with general models and get prediction scores which will be used to send the messages. And the whole process just goes on and on daily, continuously and incrementally train the model to get a more accurate results.What are the challenges?
- SMS services have to support about a hundred million records in a single table and a pretty high input rate.
- Tune the hologres. Tune the kafka.
- Records are archived into a partition table to ease the pressure.
Availability.
The correctness of checking the vendors’ receipts of messages. Double check.
How to guarantee the consumed quotas are metered and pushed correctly.
How to connect our product to the billing system, the authentication system (RAM&STS), the unified API gateway of Alibaba Cloud, not difficult but complex.
Performance for large scale database and high throughput.
So basically you’re doing the job of gluing those product together? Sort of but not all. What we do here is to tune the products to adapt our products and requirements.
- Hologres Distributed large scale database support postgres query executor.
- Kafka Distributed message queue. With ACK all by default.
- MaxCompute Hive like analytic table and distributed execution engine on spark.
How do you know about spark? Distributed training?
How about the jobs, the training jobs are hosted in the another product of our department. So the things here we need to do is monitor the job status and grep the results back.
Launch the jobs.
Why do?
that’s one part of our revenue.
# 推荐引擎
联合开发。使用Go开发,支持外接微服务与数据源,使用标准化模块化设计,可结合通用与业务自定义快速适配发布,支持多路召回(协同过滤,向量),过滤(分页,曝光,去重),离在线特征加载,客户端/服务端实时特征拼接,多路打分,排序(精排,粗排,重排),AB测试,Tracing等功能。使用并行,缓存,批处理,预热等方法提升性能,通过熔断、限流、fallback等方法防止雪崩。配合离在线算法模型在跨境电商、短视频、游戏分发平台落地,业务指标提升满足客户需求。
The engine is developed in Go, and supports external microservices and data sources. Followed the design principles of standardization and modularity, we can combine general modules and custom modules to quickly adapt and release. The engine supports multi-channel recall (CF, embedding), filtering (paging, exposure, deduplication), offline/online feature loading, client/server-side real-time feature concatenation, multi-way scoring, ranking (refined ranking, re-ranking, weighting), AB test and tracing. We improved the performance by parallel and batch processing, cache and warm-up, and guaranteed availability using time-out, circuit breaker, rate limiter, and service downgrade. Combined with manual modeling and integrated with customer’s data system, it has been adopted on cross-border e-commerce, short video, and game distribution platforms, and meets the business requirements.
-
Why? What? How?
We found that a lot of traditional companies have the requirements of using data to improve the business indicators but lack the ability from the data collection, modeling, development of recommend service etc. Lack the basic knowledge of recommendation engine.
What’s the challenge?
To design a engine with maximum flexibility and performance. This is not the key factor.
开发工程师 2018-2020
C++/Python/Tensorflow/PyTorch/TensorRT/Verilog
# 推理优化
基于社区、厂商与自研方案,与深度学习产品EAS整合,提供算子、计算图、系统级别的优化能力。算子层面,使用FPGA定制、TVM、MKL-DNN、量化等方案对业务模型中的高频算子集中优化;计算图层面,使用定制子图模式匹配、TensorRT、XLA等方案融合子图;系统层面通过精简数据格式、统一线程池、绑核、网络直连、缓存、预热、弹性调度等方案,硬件不变的条件下模型加速比在2-10倍左右,系统端到端RT下降20%-80%,吞吐提高1.1-3倍,降低成本支持超卖。
The solutions consist of community, vendor and self-developed schemes and have been integrated with the model serving platform EAS to provide optimization capabilities at the operator, computational graph, and system levels. At the operator level, FPGA, TVM, MKL-DNN and quantization are used to optimize the common operators in the business model. At the computational graph level, pattern matching, TensorRT, XLA are used for subgraph fusion; At the system level, optimization methods include simplified data format, unified thread pool, core binding, network direct connecting, cache, warm-up, and elastic scaling. The acceleration ratio is about 2-10x using the same hardware, and the end-to-end latency is reduced by 20-80%, the throughput is increased by 1.1-5x and the cost is reduced to support oversold.
# 硬件加速
基于FPGA开发的自研推理加速芯片解决方案,使用Verilog编写卷积以及长尾算子硬件逻辑,使用C++编写运行时和编译器,通过自定义算子和XLA等方式接入TensorFlow,支持CNN、推荐类模型,加速比可能达数十到数百倍。
This solution is developed on FPGA, using Verilog to implement the convolution and other compute-intensive operators’ logics, using C++ to develop runtime and compiler and integrated in TensorFlow through custom operators and XLA, supporting CV, speech and recommendation models. The speedup is about several to hundreds of times.
# Q&A
# Video Enhancement
# 分布式任务系统
-
1 分布式任务是怎么实现的?基于 Job 还是 Service?
使用k8s的job和service来实现,自动调度和资源分配。
-
1.1 如果基于Job,怎么怎么避免image pull的overhead?
有两点,一个我们是基于ECI和ECS开发的,ECI是Elastic Container Image,负责弹性,ECS负责固定,ECI提供了ImageCache功能避免Image Pull。另一点是我们提前预热拉取image,随后就不需要了。
-
1.1.1 ImageCache的原理是什么?
一般情况下,k8s的node是VM,也就对应一个VM image,而eci维持了一个VM的pool,可以直接分配给第三方集群,同时提前制作一个ImageCache就相当于提前打包了一个包含目标docker image的VM image,启动pod时,eci会通过docker image的特征值查找对应的VM image,如果找到了就直接用对应的VM image,如此ECI就会assign pod到使用对应VM image的VM Node上,避免了每次的docker image重复拉取。基本上ImageCache可以做到30s内的启动。相对于ECS的弹性和docker image需要数分钟时间的启动过程,已经比较快了。
-
1.2 GPU在Pulling的时候占用Node吗?
问题在问Pod的生命周期[2],容器Pulling的时候,Pod已经Scheduled了,Pod处于Pending状态。Pod处于Succeeded或Failed状态时释放资源。
-
⚠️2 怎么处理任务状态同步问题?
任务直连数据库。
-
2.1 数据库连接数满了怎么办?你这个方案最多能支持多少任务并行?如果连接数满了,状态会不会丢,会不会卡任务?
扩容数据库?取决于连接数,会存在你说的情况。
-
2.1.1 可以优化一下吗?
使用状态写入服务批量写入,任务retry,可以扩容。但是实际还是出现了状态同步丢失的情况。
或许可以状态写入服务可以加一个消息队列缓冲一下,from 3。 -
2
-
⚠️3 如果是Service怎么实现的?
每个Service从数据库读取任务并且同步状态。
-
3.1 服务之间会重复读取吗?
有可能,需要加个分布式锁。
-
⚠️3.1.1 怎么加分布式锁?
- ZooKeeper的临时顺序节点
- Redis的setnx()、expire() 或者 setnx()、get()、getset()做分布式锁。
- Etcd[5]
Lease 机制:即租约机制(TTL,Time To Live),Etcd 可以为存储的 KV 对设置租约,当租约到期,KV 将失效删除;同时也支持续约,即 KeepAlive。
Revision 机制:每个 key 带有一个 Revision 属性值,etcd 每进行一次事务对应的全局 Revision 值都会加一,因此每个 key 对应的 Revision 属性值都是全局唯一的。通过比较 Revision 的大小就可以知道进行写操作的顺序。
在实现分布式锁时,多个程序同时抢锁,根据 Revision 值大小依次获得锁,可以避免 “羊群效应” (也称 “惊群效应”),实现公平锁。
Prefix 机制:即前缀机制,也称目录机制。可以根据前缀(目录)获取该目录下所有的 key 及对应的属性(包括 key, value 以及 revision 等)。
Watch 机制:即监听机制,Watch 机制支持 Watch 某个固定的 key,也支持 Watch 一个目录(前缀机制),当被 Watch 的 key 或目录发生变化,客户端将收到通知。分布式锁需要满足:
- 互斥性: 任意时刻,只有一个客户端能持有锁。
- 锁超时释放:持有锁超时,可以释放,防止不必要的资源浪费,也可以防止死锁。
- 可重入性:一个线程如果获取了锁之后,可以再次对其请求加锁。
- 高性能和高可用:加锁和解锁需要开销尽可能低,同时也要保证高可用,避免分布式锁失效。
- 安全性:锁只能被持有的客户端删除,不能被其他客户端删除
# ZooKeeper
-
3.1.2 ZooKeeper知道吗?介绍一下加锁原理?ZooKeeper是Kafka的基本组件。
Zookeeper可以创建ephemeral sequence node,当多个客户端发起创建请求时,zookeeper会根据先后顺序创建一系列自增序号的ephemeral node,客户端获取同级兄弟节点,如果自己的序号是最小的,则说明加锁成功,否则向当前最小的节点注册监听器,当最小的节点被移除时,再次判断是否是序号最小的。
pros: 有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
cons: 性能上可能并没有缓存服务那么高,因为每次在创建锁和释放锁的过程中,都要动态创建、销毁临时节点来实现锁功能。ZK 中创建和删除节点只能通过 Leader 服务器来执行,然后将数据同步到所有的 Follower 机器上。还需要对 ZK的原理有所了解。 -
3.1.2.1 ZooKeeper怎么用的?API有哪些?
create_node flag.Ephemeral flag.Sequence
set_node
get_node -
3.1.2.2 ZooKeeper有哪些应用?
- 分布式锁
- 分布式协调
- 发布订阅
- 命名服务
-
3.1.2.3 ZooKeeper 集群,ZooKeeper是怎么保证高可用的?
-
ZAB协议
Leader,Follower,Observer模式。Observer不参与投票。
当Leader挂掉之后,进入恢复模式。- 选举出来的Leader的zxid一定要是所有的Follower中最大的
- 并且已有超过半数的Follower返回了ACK,表示认可选举出来的Leader
选举出新Leader之后,进入广播模式。使用2PC(两阶段提交)保证可靠性(一致性)。n/2+1个ACK回复才提交。
-
Leader election
-
Discovery (E#epoch establish)
-
Synchronization (5X#sync with followers)
-
Broadcast
-
-
3.1.2.4 如何部署ZooKeeper集群?
参考[8]
没有实际部署过,但基于k8s应该有可用的operator。或者自己使用StatefulSet部署。
# Redis Distributed Lock
-
3.1.3 Redis是怎么加锁的?具体说说会有什么问题吗?
方案一:SETNX + EXPIRE
setnx(lockkey, 1),因为操作是原子的,如果返回 0,则说明占位失败;如果返回 1,则说明占位成功在setnx之后如果redis挂掉了就会发生死锁。
可以用expire命令对lockkey设置超时时间。
但是这样做如果redis在setnx与expire之间挂掉也会死锁。
方案二:可以用setnx()、get()、getset()组合拳。SETNX + value值是(系统时间+过期时间)
- setnx(lockkey, 当前时间+过期超时时间),如果返回 1,则获取锁成功;如果返回 0 则没有获取到锁,转向 2。
- get(lockkey) 获取值 oldExpireTime ,并将这个 value 值与当前的系统时间进行比较,如果小于当前系统时间,则认为这个锁已经超时,可以允许别的请求重新获取,转向 3。
- 计算 newExpireTime = 当前时间+过期超时时间,然后 getset(lockkey, newExpireTime) 会返回当前 lockkey 的值currentExpireTime。
- 判断 currentExpireTime 与 oldExpireTime 是否相等,如果相等,说明当前 getset 设置成功,获取到了锁。如果不相等,说明这个锁又被别的请求获取走了,那么当前请求可以直接返回失败,或者继续重试。
- 在获取到锁之后,当前线程可以开始自己的业务处理,当处理完毕后,比较自己的处理时间和对于锁设置的超时时间,如果小于锁设置的超时时间,则直接执行 delete 释放锁;如果大于锁设置的超时时间,则不需要再锁进行处理。
pros: 解决了方案一的问题
cons:- 过期时间是客户端自己生成的(System.currentTimeMillis()是当前系统的时间),必须要求分布式环境下,每个客户端的时间必须同步。
- 如果锁过期的时候,并发多个客户端同时请求过来,都执行jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖
- 该锁没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
方案三:使用Lua脚本(包含SETNX + EXPIRE两条指令)
lua保证原子性,可查看redis lua指南[9]
1
2
3
4
5if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then
redis.call('expire',KEYS[1],ARGV[2])
else
return 0
end;加锁代码如下:
1
2
3
4
5String lua_scripts = "if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then" +
" redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end";
Object result = jedis.eval(lua_scripts, Collections.singletonList(key_resource_id), Collections.singletonList(values));
//判断是否成功
return result.equals(1L);但保证原子性还不够,还有和方案四一样的缺点。
方案四:SET的扩展命令(SET EX PX NX)引入setnx expire的原子操作
SET key value[EX seconds][PX milliseconds][NX|XX]NX :表示key不存在的时候,才能set成功,也即保证只有第一个客户端请求才能获得锁,而其他客户端请求只能等其释放锁,才能获取。
EX seconds :设定key的过期时间,时间单位是秒。
PX milliseconds: 设定key的过期时间,单位为毫秒
XX: 仅当key存在时设置值jedis.set(key_resource_id, lock_value, "NX", "EX", 100s)cons:
- 问题一:锁过期释放了,业务还没执行完。假设线程a获取锁成功,一直在执行临界区的代码。但是100s过去后,它还没执行完。但是,这时候锁已经过期了,此时线程b又请求过来。显然线程b就可以获得锁成功,也开始执行临界区的代码。那么问题就来了,临界区的业务代码都不是严格串行执行的啦。
- 问题二:锁被别的线程误删。假设线程a执行完后,去释放锁。但是它不知道当前的锁可能是线程b持有的(线程a去释放锁时,有可能过期时间已经到了,此时线程b进来占有了锁)。那线程a就把线程b的锁释放掉了,但是线程b临界区业务代码可能都还没执行完呢。
方案五:SET EX PX NX + 校验唯一随机值,再删除
jedis.set(key_resource_id, uni_request_id, "NX", "EX", 100s)1
2
3
4//判断是不是当前线程加的锁,是才释放
if (uni_request_id.equals(jedis.get(key_resource_id))) {
jedis.del(lockKey); //释放锁
}cons: 判断是不是当前线程加的锁和释放锁不是一个原子操作。
可以用lua脚本代替:
1
2
3
4
5if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;方案六:Redisson框架[10]
方案五还是可能存在锁过期释放,业务没执行完的问题。有些小伙伴认为,稍微把锁过期时间设置长一些就可以啦。其实我们设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
当前开源框架Redisson解决了这个问题。只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。Go version of redisson[11]
1
2
3LockScript = "if redis.call('exists', KEYS[1]) == 0 then return redis.call('setex', KEYS[1], unpack(ARGV)) else return '-1' end"
UnlockScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) or true end"
RenewLockScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('expire', KEYS[1],ARGV[2]) or true end"方案七:多机实现的分布式锁Redlock+Redisson
前面六种方案都只是基于单机版的讨论,还不是很完美。其实Redis一般都是集群部署的:
线程1,2同时向master加锁,但加锁的key还没同步到slave节点,如果此时master发生故障,slave升级为master,线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
1.获取当前时间,以毫秒为单位。
2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于三个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
# etcd分布式锁
ETCD client/v3 concurrency.Mutex
基于ETCD的选主
concurrency.NewElection
# Pipeline实现
-
3 如果是Service怎么实现的?
每个服务从任务队列里读任务,并且将状态写回消息队列。
# Kafka
-
3.1 用的什么消息队列?为什么用消息队列?
Kafka。
- Asynchronous
- Peak Clipping
- Decoupling
-
3.1.1 会重复读吗?怎么做到不重复读?
不会,把所有服务设置为同一个Comsumer Group。
-
3.1.1.1 Consumer Group是怎么实现不重复读的?
这要说道Consumer的Rebalance机制,对于Consumer Group中的每个Consumer,服务端尽量做到每个Consumer分配不同的Partition,如果P的数量>C,那一个C就可能获取多个P,反之,会有C空闲。
-
3.1.2 消息队列支持有连接数限制吗?会影响同时并行的服务数量吗?
通常建议每个broker不超过1k个客户端,因为每个客户端与broker都需要建立socket连接。当连接数过多时会消耗过多资源在Socket处理上。
-
3.1.3 Kafka的结构和运行原理知道吗?
基础的节点单位是Broker,每个Topic为一个队列,每个Topic会分为多个Partition,一个Partition有至少三个副本分布在不同Broker上,其中一个是Leader,其他两个是Follower,Leader负责处理对Partition的操作,Follower同步复制操作。ZooKeeper负责处理分布式节点监控与恢复以及Leader失效后重新选出新Leader。对于客户端,Producer负责写入数据,并且尽可能均匀的写入Partition,如果Key不null,根据Key的Hash值计算分区号,如果Key null,则轮询写入。Consumer负责读取数据,通过Rebalance获取自己在Consumer Group中可以读取的Partition序号,顺序读取数据。
-
3.1.4 Kafka保序吗?如何保序?
参考[12]。Kafka分布式的单位是Partition,同一个Partition可以保证FIFO,不同Partition之间不能保证顺序。但是可以通过message key来保序,同一个key只会发送到同一个partition,能保证同一个key的message是保序的。同时如果需要所有信息严格保序,只设置一个partition即可。
-
3.1.4.1 如果Key Skew了怎么办?
区分原因,如果Key分布相对均匀,可以换Hash函数,如果Key分布不均匀,考虑去掉Key,或者重新选择Key,比如uid换成order id之类的。
-
⚠️3.1.4.1.1 Kafka常用的Key Hash函数有哪些?
- murmur2
-
3.1.5 Rebalance是什么?讲讲具体过程?如何避免Rebalance?
参考[12:1][13]。
Rebalance发生在以下情况,需要避免:- Consumer加入或退出或无心跳之后
- 在Partition数量变更之后
- 订阅主题数变更。在使用正则匹配Topic时新增了Topic订阅Topic数量发生改变之后
-
⚠️3.1.5.1 Rebalance策略有哪些?各自的优缺点是什么?
[13:1]
Range
pros: 单个Topic分配均匀,但当加入或移除consumer时,会大范围重分配。
cons: 如果订阅了多个Topic,字典序靠前的消费组中的消费者比较 “ 贪婪 ” ,因此Consumer负载不均衡。RoundRobin
RoundRobinAssignor 的分配策略是将消费组内订阅的所有 Topic 的分区及所有消费者进行排序后尽量均衡的分配(RangeAssignor 是针对单个 Topic 的分区进行排序分配的)
pros: 单个Topic分配均匀。多个Topic,尽量分配平衡。
cons: 对于消费组内消费者订阅 Topic 不一致的情况,还是会出现不均衡。C0->T1{0,1,2},T2{0} C1->T2{1}Sticky
尽管 RoundRobinAssignor 已经在 RangeAssignor 上做了一些优化来更均衡的分配分区,但是在一些情况下依旧会产生严重的分配偏差,比如消费组中订阅的Topic 列表不相同的情况下。 更核心的问题是无论是RangeAssignor ,还是 RoundRobinAssignor ,当前的分区分配算法都没有考虑上一次的分配结果 。显然,在执行一次新的分配之前,如果能考虑到上一次分配的结果,尽量少的调整分区分配的变动,显然是能节省很多开销的。- 分区的分配尽量的均衡
- 每一次重分配的结果尽量与上一次分配结果保持一致
当这两个目标发生冲突时,优先保证第一个目标。第一个目标是每个分配算法都尽量尝试去完成的,而第二个目标才真正体现出StickyAssignor 特性的。
-
3.1.6 Kafka怎么实现超高并发/吞吐的?为什么这么快?
- 分区数据并行处理。
- Partition顺序写入磁盘。
- 利用PageCache批量写入磁盘。
- 零拷贝技术。
- 批量发送读取。
- 数据压缩节省磁盘网络延迟。
- reactor模式,I/O多路复用[14]。
# RocketMQ
-
⚠️3.1.7 知道其他消息队列吗?为什么不用?
RabbitMQ,RocketMQ。
- 团队中目前已经有了Kafka集群,可以复用。
- 经过调研,Kafka可以满足需求。暂时没有消息超时等需求。
- 在保证可靠性的情况下,Kafka的性能和其他队列差不多。
-
3.1.7.1 RocketMQ有什么优势?
-
3.1.7.2 RocketMQ是什么架构?
-
3.1.8 如何保证幂等性?也就是不重复消费?
-
3.1.9 如果MQ挂了怎么办?整个系统就挂了吗?
- MQ确实有可能挂掉,是一种正常现象。只不过是说这个挂的概率非常小,毕竟都是集群模式。
- 统一封装MQ的操作
- 降级,可以用sentinel熔断
- 降级处理,数据存储
- 写数据库
- 写磁盘
- 写日志
- 重发消息
- 可以单独起一个定时任务,周期性的去将这些失败存储的消息进行重发,如果你的MQ服务故障后几分钟就恢复了,那么重试的时候消息就能够成功发出去了。
- 也可以人工处理,最重要的是当MQ故障的时候,消息发送不出去,这些消息要存储起来,不能丢失,这才是重点。
# Kafka
-
3.1.10 怎么保证Kafka消息不丢失?
Producer
配置ack=-1,保证写入所有follower之后返回,延迟更大
Consumer
关闭自动offset commit,手动提交
Broker
partition replication参考[20]
-
3.1.11 Kafka怎么选举的?
参考[21]
-
3.1.12 Kafka用的哪个库?为什么?
segmentio/kafka-go,是一个纯Go实现的客户端,可以在多端上测试运行,免去了CGo的依赖,性能实际使用下来时足够的。
-
3.1.13 Kafka的MirrorMaker知道吗?用过吗?
用于异地复制,在不同集群间同步。
-
⚠️3.2 如何区分优先级?
-
⚠️3.3 如何区分不同用户?每个用户应该有自己的任务队列,否则一个用户可能会耗尽资源。
# Exception Handling
-
3.4 如果临时终止任务怎么处理?
使用KILL TASK队列,每个Service 作为单独的Consumer读取,如果TASK ID和当前正在处理的任务一致则终止任务,并发送任务状态。
-
3.5 如何处理失败任务?
加异常处理,因各种原因失败的任务发送任务状态,以及失败原因。
-
3.6 如何处理节点突然失效?
如果是Node失效或Pod Crash,k8s的重启机制会保证Service重启,重新订阅Topic。如果是Pod本身卡死,则需要发送心跳包,维护一个在线Service列表,一旦心跳包超时则需要重启Service。Task心跳包超时后需重新下发Task。
-
3.7 怎么添加监控的?监控了什么指标?如何Alert?
监控Service状态,当前各状态的Task数量分布,输入输出视频的平均码率。
-
⚠️3.8 为什么不用成熟的任务调度框架?
# Update Model
-
3.9 怎么更新服务和模型的?
使用k8s的rolling update更新。
在大版本更新时,手动操作使用灰度发布,金丝雀发布和蓝绿发布。
保持模型版本号,每个job对应一个模型版本号。在更新时会将当前default模型升级。
-
3.9.1 模型切换会有代价吗?
模型初始化会有overhead,数据下载也有overhead,但并不是特别大。
-
3.10 可以给不同用户使用不同模型吗?
different service。在job的配置里加入model,如果model已在本地,且md5对得上,则用本地model。
专用model匹配专用worker pool。
# Video Processing
-
4 视频的处理过程是怎样的?能详细说说吗?
Netflix系统设计参考[22],值得借鉴的是
- 拆分大文件为小块。视频处理时间比与视频编码质量折衷。如果处理单一大视频文件,如果要求极高编码质量,只能通过ffmpeg软编码,我们尝试了多种编码器,比如NVIDIA NVENC,Intel的QSV等。
视频处理分两阶段,先做模型处理,再做编码压缩。模型处理服务初始化或者更新的时候首先加载模型,使用OpenCV读取视频,并根据视频尺寸Batch化,根据GPU Memory大小,每种尺寸对应不同的Batch Size,防止OOM。处理好的视频OpenCV以无损格式写出。处理完成后的视频传输至Object Storage,我们搭建了一个VPC内的minio作为视频交换媒介。编码服务拉取视频并根据配置编码,回传至Object Storage,并回调通知用户服务。
-
4.1 无损格式写出的中间视频体积很大,会消耗存储和传输资源,这部分可以怎么避免吗?Minio没有出现过带宽瓶颈吗?
开始会出现瓶颈,发现还是通过Volume Share避免网络传输。
-
4.2 有哪些优化方式,视频分割。
# Network
-
5 网络基本知识
-
5.1 HTTP格式?
-
5.2 HTTPS基本原理?如何加密的?
-
5.3 长轮询怎么做?什么原理?
-
5.4 Websocket用过吗?
-
5.5 如果用户跨地区国家,怎么同步不同地区间的数据?也就是异地多活?
-
5.6 RPC什么原理?知道什么框架?和RESTful对比?
# Modeling
-
1 模型基本结构是什么?效果如何?有什么评价指标吗?
-
2 主流的超分或者视频增强模型有哪些?结构上有什么不同?可以用Transformer吗?
-
3 用什么方法避免ringing effect和artifact伪影呢?
-
4 用的什么Loss?
-
5 为什么要用GAN?用了有什么效果?
-
6 用了什么退化?
# Distributed Training
- 7 怎么训练的?分布式?为什么不用集群?
# Video Encoding
-
1 ffmpeg编码质量怎么配置的?有改过代码吗?
-
2 用的什么编码?H264还是H265。
-
3 编码时间比是多少?怎么加速?
# Intelligent Marketing Platform
# High Throughput
-
1 怎么支撑这么高的并发的?
通过5点:
- API-Server是无状态Deployment服务,可以扩容并行处理输入。
- 发送短信时需要阿里云鉴权,验证签名和模板的有效性,我们使用了阿里云本地的鉴权客户端,并且加了签名模板等资源的本地缓存,保证基本不读取数据库。
- 在API侧写数据库压力很大,并且因为API限制了每次请求batch数量,写入数据库的query碎片化,所以直接写入Kafka,等到发送完成后再写入数据库。这样就避免了同一条短信数据的两次数据库写入操作,节省了数据库带宽。
- 一开始是以短信为单位写入Kafka,发现写入和读取的速度相对比较慢,后面优化为以用户请求batch为单位为Kafka的一条信息,读写的速度有了明显提高,不再是瓶颈。
- 多协程操作,大batch化操作数据库,利用GoRoutine处理数据,放入写数据库channel中积累到一定数据或达到超时阈值后统一写回数据库。大Batch相比多次小Batch延迟明显降低。
-
2 有做流控吗?怎么做的?
有做,分别在网关层,API输入层,短信发送层做了流控。
- 网关层是阿里云提供的系统级流控,包括产品级与API级访问控制。
- Ingress层,Nginx-Ingress
- API层使用Sentinel-Go做流控,基本原理是滑动窗口和队列。
- 短信发送层配置短信发送速率,这是因为下游服务提供商没有提供有效的队列,当发送速率过高时短信的发送失败率过高。
流控方法基本上就是滑动窗口法和漏桶法。
-
2.1 讲讲Sentinel?
参考[24]
-
2.1.2 Sentinel是分布式的吗?
可以结合HASA阿里服务。
-
2.2 常用的限流方法?
固定窗口法 Fixed Window
滑动窗口法 Slide Window
漏桶法 Leaky Bucket
令牌桶 Token Bucket -
2.3 分布式流控方案?
Redis + Lua + 令牌桶
Redis分布式限流器
分布式服务限流实战,已经为你排好坑了 -
3 数据库有遇到瓶颈吗?Latency平均在多少?为什么不用MySQL/MongoDB/HBase之类的?
# Hologres
-
4 介绍一下Hologres的原理?
数据类型
Hologres存储引擎的基本抽象是分布式的表,为了让系统可扩展,我们需要把表切分为分片(Shard)。 为了更高效地支持JOIN以及多表更新等场景,用户可能需要把几个相关的表存放在一起,为此Hologres引入了表组(Table Group)的概念。分片策略完全一样的一组表就构成了一个表组,同一个表组的所有表有同样数量的分片。用户可以通过“shard_count"来指定表的分片数,通过“distribution_key"来指定分片列。目前我们只支持Hash的分片方式。
表的数据存储格式分为两类,一类是行存表,一类是列存表,格式可以通过“orientation"来指定。
每张表里的记录都有一定的存储顺序,用户可以通过“clustering_key"来指定。如果没有指定排序列,存储引擎会按照插入的顺序自动排序。选择合适的排序列能够大大优化一些查询的性能。
表还可以支持多种索引,目前我们支持了字典索引和位图索引。用户可以通过“dictionary_encoding_columns"和“bitmap_columns"来指定需要索引的列。
存储引擎架构
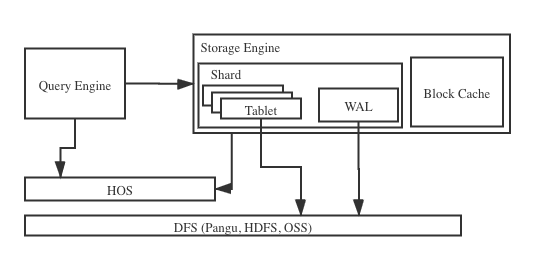
每个分片(Table Group Shard, 简称Shard)构成了一个存储管理和恢复的单元 (Recovery Unit)。上图显示了一个分片的基本架构。一个分片由多个tablet组成,这些tablet会共享一个日志(Write-Ahead Log,WAL)。存储引擎用了Log-Structured Merge (LSM)的技术,所有的新数据都是以append-only的形式插入的。 数据先写到tablet所在的内存表 (MemTable),积累到一定规模后写入到文件中。当一个数据文件关闭后,里面的内容就不会变了。新的数据以及后续的更新都会写到新的文件。 与传统数据库的B±tree数据结构相比,LSM减少了随机IO,大幅的提高了写的性能。
当写操作不断进来,每个tablet里会积累出很多文件。当一个tablet里小文件积累到一定数量时,存储引擎会在后台把小文件合并起来 (Compaction),这样系统就不需要同时打开很多文件,能减少使用系统资源,更重要的是合并后, 文件减少了,提高了读的性能。
在DML的功能上,存储引擎提供了单条或者批量的创建,查询,更新,和删除(CRUD操作)访问方法的接口,查询引擎可以通过这些接口访问存储的数据。
下面是存储引擎几个重要的的组件:
-
WAL 和 WAL Manager
WAL Manager是来管理日志文件的。存储引擎用预写式日志(WAL) 来保证数据的原子性和持久性。当CUD操作发生时,存储引擎先写WAL,再写到对应tablet的MemTable中,等到MemTable积累到一定的规模或者到了一定的时间,就会把这个MemTable切换为不可更改的flushing MemTable, 并新开一个 MemTable接收新的写入请求。 而这个不可更改的flushing MemTable就可以刷磁盘,变成不可更改的文件; 当不可更改的文件生成后,数据就可以算持久化。 当系统发生错误崩溃后,系统重启时会去WAL读日志,恢复还没有持久化的数据。 只有当一个日志文件对应的数据都持久化后,WAL Manager才会把这个日志文件删除。 -
文件存储
每个tablet会把数据存在一组文件中,这些文件是存在DFS里 (阿里巴巴盘古或者Apache HDFS )。 行存文件的存储方式是Sorted String Table(SST) 格式。 列存文件支持两种存储格式: 一种是类似PAX的自研格式, 另外一种是改进版的Apache ORC格式 (在AliORC的基础上针对Hologres的场景做了很多优化)。 这两种列存格式都针对文件扫描的场景做了优化。 -
Block Cache (Read Cache)
为了避免每次读数据都用IO到文件中取,存储引擎通过BlockCache把常用和最近用的数据放在内存中,减少不必要的IO,加快读的性能。在同一个节点内,所有的Shard共享一个Block Cache。 Block Cache有两种淘汰策略: LRU (Least Recently Used,最近最少使用) 和 LFU (Least Frequently Used, 最近不常用)。 顾名思义,LRU算法是首先淘汰最长时间未被使用的Block,而LFU是先淘汰一定时间内被访问次数最少的Block。
Distributed Database With PostgreSQL Query Engine Support. Hologres divides data into different shards by hashing the key, stores data into DFS(Pangu,HDFS,OSS) and aggregates the results from different shards. and provides dictionary index and bitmap index to accelerate the execution. A shard consists of multiple tablets. And those tablets shares a common write-ahead log (WAL for short).
读写原理
Hologres支持两种类型的写入:单分片写入和分布式批量写入。两种类型的写入都是原子的(Atomic Write),即写入或回滚。单分片写入一次更新一个Shard,但是需要支持极高的写入频率。另一方面,分布式批写用于将大量数据作为单个事务写到多个Shard中的场景,并且通常以低得多的频率执行。
- 单分片写入
如上图所示,WAL管理器在接收到单分片写请求后,(1)为写请求分配一条Log Sequence Number (LSN),这个LSN是由时间戳和递增的序号组成,并且(2)创建一条新的日志,并在文件系统中的持久化这条日志。这条日志包含了恢复写操作所需的信息。在完全保留这条日志后,才向tablet提交写入。之后,(3)我们会在相应tablet的内存表(MemTable) 中执行这个写操作,并使其对新的读请求可见。值得注意的是,不同tablet上的更新可以并行化。当一个MemTable满了以后,(4)将其刷新到文件系统中,并初始化一个新的MemTable。最后,(5)将多个分片文件在后台异步合并(Compaction)。在合并或MemTable刷新结束时,管理tablet的元数据文件将相应更新。 - 分布式批量写入
接收到写入请求的前台节点会将写请求分发到所有相关的分片。这些分片通过两阶段提交机制(Two Phase Commit) 来保证分布式批量写入的写入原子性。 - 多版本读
Hologres支持在tablet中多版本读取数据。读请求的一致性是read-your-writes,即客户端始终能看到自己最新提交的写操作。每个读取请求都包含一个读取时间戳,用于构造读的snapshot LSN。如果有一行数据的LSN大于snapshot LSN的记录, 这行数据就会被过滤掉, 因为他是在读的snapshot产生后才被插入到这个tablet的。
技术亮点
1)存储计算分离
存储引擎采取存储计算分离的架构,所有的数据文件存在一个分布式文件系统(DFS, 例如阿里巴巴盘古或者Apache HDFS)的里面。当查询负载变大需要更多的计算资源的时候可以单独扩展计算资源; 当数据量快速增长的时候可以快速单独扩展存储资源。计算节点和存储节点可以独立扩展的架构保证了不需要等待数据的拷贝或者移动就能快速扩展资源; 而且,可以利用DFS存多副本的机制保证数据的高可用性。 这种架构不但极大地简化了运维,而且为系统的稳定性提供了很大的保障。2)异步执行流程
存储引擎采用了基于事件触发, 非阻塞的纯异步执行架构, 这样能够充分发挥现代CPU多core的处理能力,提高了吞吐量, 支持高并发的写入和查询。这种架构得益于HOS(HoloOS) 框架,HOS在提供高效的异步执行和并发能力的同时,还能自动地做CPU的负载均衡提升系统的利用率。3)统一的存储
在HSAP场景下,有两类查询模式,一类是简单的点查询(数据服务Serving类场景),另一类是扫描大量数据的复杂查询(分析Analytical类场景)。 当然,也有很多查询是介于两者之间的。这两种查询模式对数据存储提出了不同的要求。行存能够比较高效地支持点查询,而列存在支持大量扫描的查询上有明显的优势。
为了能够支持各种查询模式,统一的实时存储是非常重要的。存储引擎支持行存和列存的存储格式。根据用户的需求,一个tablet可以是行存的存储格式 (适用于Serving的场景); 也可以是列存的存储格式(适用于Analytical的场景)。 比如,在一个典型HSAP的场景,很多用户会把数据存在列存的存储格式下,便于大规模扫描做分析;与此同时,数据的索引存在行存的存储格式下,便于点查。并通过定义primary key constraint (我们是用行存来实现的)用来防止数据重复·。不管底层用的是行存还是列存,读写的接口是一样的,用户没有感知,只在建表的时候指定即可。4)读写隔离
存储引擎采用了snapshot read的语意,读数据时采用读开始时的数据状态,不需要数据锁,读操作不会被写操作block住; 当有新的写操作进来的时候,因为写操作是append-only,所有写操作也不会被读操作block住。这样可以很好的支持HSAP的高并发混合工作负载场景。5)丰富的索引
存储引擎提供了多种索引类型,用于提升查询的效率。一个表可以支持clustered index 和 non-clustered index这两类索引。一个表只能有一个clustered index, 它包含表里所有的列。一个表可以有多个non-clustered indices。在non-clustered indexes里,除了排序用的non-clustered index key外,还有用来找到全行数据的Row Identifier (RID)。 如果clustered index存在, 而且是独特的,clustered index key就是RID; 否则存储引擎会产生一个独特的RID。 为了提高查询的效率,在non-clustered index中还可以有其他的列, 这样在某些查询时,扫一个索引就可以拿到所有的列的值了 (covering index)。在数据文件内部,存储引擎支持了字典和位图索引。字典可以用来提高处理字符串的效率和提高数据的压缩比,位图索引可以帮助高效地过滤掉不需要的记录。
Hologres 是能够弹性无限水平扩展数据量和计算能力的系统,需要能够支持高效的分布式查询。
Hologres 查询引擎执行的是由优化器生成的分布式执行计划。执行计划由算子组成。因为 Hologres 的一个表的数据会根据 Distribution Key 分布在多个 Shard 上,每个 Shard 内又可以包含很多 Segment,执行计划也会反映这样的结构,并分布到数据所在的节点去执行。每个Table Shard 会被加载到一个计算节点,数据会被缓存到这个节点的内存和本地存储。因为是存储计算分离的架构,如果一个节点出错,其服务的 Shard 可以被重新加载到任意一个计算节点,只是相当于清空了缓存。Hologres揭秘:实时数仓Hologres如何支持超大规模部署与运维
Kubernetes万台调度
Kubernetes官方公布集群最大规模为5000台,而在阿里云场景下,为了满足业务规模需求、资源利用率提升等要求,云原生集群规模要达万台。众所周知Kubernetes是中心节点式服务,强依赖ETCD与kube-apiserver,该块是性能瓶颈的所在,突破万台规模需要对相关组件做深度优化。同时要解决单点Failover速度问题,提升云原生集群的可用率。
通过压测,模拟在万台node和百万pod下的压力,发现了比较严重的响应延迟问题,包括:- etcd大量的读写延迟,并且产生了拒绝服务的情形,同时因其空间的限制也无法承载 Kubernetes 存储大量的对象;
- API Server 查询延迟非常高,并发查询请求可能导致后端 etcd oom;
- Controller 处理延时高,异常恢复时间久,当发生异常重启时,服务的恢复时间需要几分钟;
- Scheduler 延迟高、吞吐低,无法适应业务日常运维的需求,更无法支持大促态的极端场景
为了突破k8s集群规模的瓶颈,相关团队做了详细调研,找到了造成处理瓶颈的原因: - 发现性能瓶颈在kubelet,每10s上报一次自身全量信息作为心跳同步给k8s,该数据量小则几KB大则10KB+,当节点到达5000时,会对kube-apiserver和ETCD造成写压力。
- etcd 推荐的存储能力只有2G,而万台规模下k8s集群的对象存储要求远远超过这个要求,同时要求性能不能下降;
- 用于支持集群高可用能力的多API Server部署中,会出现负载不均衡的情况,影响整体吞吐能力;
- 原生的scheduler 性能较差,能力弱,无法满足针对混部、大促等场景下的能力。
针对该情况,做了如下优化,从而达到万台规模调度: - etcd设计新的内存空闲页管理算法,大幅优化etcd性能;
- 通过落地 Kubernetes 轻量级心跳、改进 HA 集群下多个 API Server 节点的负载均衡,解决了APIServer的性能瓶颈;
- 通过热备的方式大幅缩短了 controller/scheduler 在主备切换时的服务中断时间,提高了整个集群的可用性;
- 通过支持等价类处理以及随机松弛算法的引入,提升了Scheduler的调度性能
-
-
4.1 Hologres的行存列存数据格式?
行存 Sorted String Table(SST)每个日志结构的存储段都是一组 key-value 对的序列,按照写入顺序排列,并且对于段内日志中的同一个键,后出现的值优于之前的值。
当段文件达到一定大小之后就会关闭它,并生成一个新的段文件,一般大小为64KB。随着写入数据的不断追加,段文件不断增多。段内重复的键和段间重复的键不断增多。然后可以在这些段上执行压缩(有些存储引擎叫重写),压缩意味着在日志中丢弃重复的键,仅保留每个键最近的更新。这样既可以使段更小,也可以在执行压缩阶段将段合并,由于段的不变性,合并的时候,需要写入到一个段文件。
在执行压缩和合并过程中,旧的段并不会被修改,依然可以继续处理读写请求。合并完成之后,就可以安全地删除旧的段文件。
至于压缩算法,往往采用可配的方式支持。Google 论文[1]中提到可以采用"两遍"方式:第一个遍采用 Bentley and McIlroy’s 方式,这种方式在一个很大的扫描窗口里对常见的长字 符串进行压缩;第二遍采用快速压缩算法,即在一个16KB的小扫描窗口中寻找重复数据。
为什么 SSTable 是不可变的?
不可变的段文件,对于并发控制和奔溃恢复非常友好。列存 Optimized Record Columnar (ORC)
Hive:ORC File Format存储格式详解(1)、每个task只输出单个文件,这样可以减少NameNode的负载;
(2)、支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union);
(3)、在文件中存储了一些轻量级的索引数据;
(4)、基于数据类型的块模式压缩:a、integer类型的列用行程长度编码(run-length encoding);b、String类型的列用字典编码(dictionary encoding);
(5)、用多个互相独立的RecordReaders并行读相同的文件;
(6)、无需扫描markers就可以分割文件;
(7)、绑定读写所需要的内存;
(8)、metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列。
# Cache
-
5 本地缓存怎么做的?
go的Cache包,设置过期时间,使用LFU淘汰策略。
-
5.1 会有数据一致性问题吗?
不会,没有强一致性要求,因为需要缓存的对象设计的时候避免了Update操作,User表在用户首次开通产品时就已经确定无法更改。Signature表与Template表同样。在前端加入了从已有新建的快捷操作。
# Redis
-
5.2 为什么不用Redis?
需要缓存的规模比较小,而且没有很强的一致性要求,所以就用了Local Cache。像用户Session信息都是由阿里云的网关服务负责的,我们产品的服务收到的请求头部里有用户相关的各类信息,比如用户主账号id,子账号id,以及一系列其他的鉴权相关的信息。
问题其实在问什么时候应该用Redis,参考[25:1],同时也是在问用Local Cache的局限性,参考[28],同时也是在问能否结合Redis与本地缓存[29][30]。 -
5.3 Redis为什么快?
- in-memory 内存不需要访问磁盘。
- single thread处理,减小多线程竞争的context switching开销,避免加锁开销以及死锁的情况。
- IO 多路复用,处理并发连接。
- 数据结构简单,操作也简单,提升性能。
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
参考[31]。
-
5.3.1 说一下Redis的内存模型?
[32]
字符串、哈希、列表、集合、有序集合
redisObject1
2
3
4
5
6
7typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;SDS
Redis没有直接使用C字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。1
2
3
4
5struct sdshdr {
int len;
int free;
char buf[];
};String
- int
- embstr 39Byte why? 39 + redisObject 16 + sds 9 jemalloc正好可以分配64字节的内存单元。
- raw len(string)>39或者modified(append)
List
- 压缩列表 ziplist
连续数组结构,节约内存,修改复杂度高
len(list) < 512 && len(str) < 64
其中,单个字符串不能超过64字节,是为了便于统一分配每个节点的长度;这里的64字节是指字符串的长度,不包括SDS结构,因为压缩列表使用连续、定长内存块存储字符串,不需要SDS结构指明长度。后面提到压缩列表,也会强调长度不超过64字节,原理与这里类似。 - 双端列表 linkedlist
保存前后向指针,节点数量多时,双端列表更好,修改增删的复杂度低于压缩列表
Hash
- 压缩列表 ziplist
len(hashtable) < 512 && len(k) < 64 && len(v) < 64 - 哈希表 hashtable
Set
- 整数集合 intset
len(set) < 512 && int - 哈希表 hashtable
SortedSet
- 压缩列表 ziplist
len(sortedset) < 128 && len(str) < 64 - 跳表 skiplist
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。具体结构相对比较复杂,略。
-
5.3.1.1 如何优化内存占用?
-
利用jemalloc特性进行优化
上一小节所讲述的90000个键值便是一个例子。由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。 -
使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。 -
共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。 -
避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
-
-
5.3.1.2 Redis内存碎片?
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。
-
5.3.2 Redis是单线程的吗?
参考[33]。Redis在处理客户端的请求时,包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。但如果严格来讲从Redis4.0之后并不是单线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 key 的删除等等。
-
5.3.2.1 为什么Redis不用多线程?
参考[34]。
官方曾做过类似问题的回复:使用Redis时,几乎不存在CPU成为瓶颈的情况, Redis主要受限于内存和网络。例如在一个普通的Linux系统上,Redis通过使用pipelining每秒可以处理100万个请求,所以如果应用程序主要使用O(N)或O(log(N))的命令,它几乎不会占用太多CPU。
使用了单线程后,可维护性高。多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。Redis通过AE事件模型以及IO多路复用等技术,处理性能非常高,因此没有必要使用多线程。单线程机制使得 Redis 内部实现的复杂度大大降低,Hash 的惰性 Rehash、Lpush 等等 “线程不安全” 的命令都可以无锁进行。
-
5.3.2.2 知道Redis 6.0之后多线程化了吗?为什么要引入多线程?
参考[34:1]。
Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis服务器可以处理80,000到100,000 QPS,这也是Redis处理的极限了,对于80%的公司来说,单线程的Redis已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的QPS。常见的解决方案是在分布式架构中对数据进行分区并采用多个服务器,但该方案有非常大的缺点,例如要管理的Redis服务器太多,维护代价大;某些适用于单个Redis服务器的命令不适用于数据分区;数据分区无法解决热点读/写问题;数据偏斜,重新分配和放大/缩小变得更加复杂等等。
从Redis自身角度来说,因为读写网络的read/write系统调用占用了Redis执行期间大部分CPU时间,瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
- 提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
- 使用多线程充分利用多核,典型的实现比如 Memcached。
协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便捷的操作方式。所以总结起来,redis支持多线程主要就是两个原因:
- 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
- 多线程任务可以分摊 Redis 同步 IO 读写负荷
-
5.3.2.3 知道怎么配置6.0的多线程吗?
Redis6.0的多线程默认是禁用的,只使用主线程。如需开启需要修改redis.conf配置文件:io-threads-do-reads yes
开启多线程后,还需要设置线程数,否则是不生效的。同样修改redis.conf配置文件。关于线程数的设置,官方有一个建议:4核的机器建议设置为2或3个线程,8核的建议设置为6个线程,线程数一定要小于机器核数。还需要注意的是,线程数并不是越大越好,官方认为超过了8个基本就没什么意义了。 -
5.3.2.4 开启多线程之后的性能如何?
Redis 作者 antirez 在 RedisConf 2019分享时曾提到:Redis 6 引入的多线程 IO 特性对性能提升至少是一倍以上。国内也有大牛曾使用unstable版本在阿里云esc进行过测试,GET/SET 命令在4线程 IO时性能相比单线程是几乎是翻倍了。
说明1:这些性能验证的测试并没有针对严谨的延时控制和不同并发的场景进行压测。数据仅供验证参考而不能作为线上指标。
说明2:如果开启多线程,至少要4核的机器,且Redis实例已经占用相当大的CPU耗时的时候才建议采用,否则使用多线程没有意义。所以估计80%的公司开发人员看看就好。 -
5.3.2.5 多线程的实现机制?
流程简述如下:
- 主线程负责接收建立连接请求,获取 socket 放入全局等待读处理队列
- 主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些 IO 线程
- 主线程阻塞等待 IO 线程读取 socket 完毕
- 主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行
- 主线程阻塞等待 IO 线程将数据回写 socket 完毕
- 解除绑定,清空等待队列
-
5.3.3 说一下什么是IO多路复用?
多路指的是多个socket连接,复用指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
-
5.3.3.1 什么是epoll?
参考[35]。
select 和 poll 是 Linux 的底层synchronous通信机制。
epoll 是改进版。
-
5.3.4 Redis的基本数据结构?底层是怎么实现的?
参考[36]。
- string
- list
- hash
- set
- sorted set
-
5.3.5 说说Redis的VM机制。
参考[37]。
Redis自己实现了一套虚拟内存的管理机制。
-
5.3.6 Redis Cluster的功能是?怎么实现的?有限制吗?可以无限扩展吗?
为了解决Redis单机容量有限的问题,提高并发量。本质上就是Sharding,在于扩展主从结构的写能力。
官方推荐最大的节点数量为1000,由于Cluster架构中无Proxy层,Master与Slave之间使用异步replication。
客户端容忍一定程度的数据丢失,集群尽可能保存Client write操作的数据,保证数据一致性。
Redis集群通过partition来提供一定程度的可用性,当集群中的一部分节点失效或者无法进行通讯时,集群仍可以继续提供服务。 -
5.3.6.1 为什么节点数量为1000?过多的节点数量会有什么问题?
Redis 集群的键空间被分割为 16384 个槽(slot), 集群的最大节点数量也是 16384 个。 推荐的最大节点数量为1000 个左右。 每个主节点都负责处理 16384 个哈希槽的其中一部分。每个 key 通过 CRC16 算法计算的结果,对 16384 取模后放到对应的编号在 0-16383 之间的哈希槽。
原作者回答:
The reason is:
Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with16k slots, but would use a prohibitive 8k of space using 65k slots.
At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.到底数据信息究竟多大?
在消息头中,最占空间的是myslots[CLUSTER_SLOTS/8]。这块的大小是:
16384÷8÷1024=2kb
那在消息体中,会携带一定数量的其他节点信息用于交换。
那这个其他节点的信息,到底是几个节点的信息呢?
约为集群总节点数量的1/10,至少携带3个节点的信息。
这里的重点是:节点数量越多,消息体内容越大。消息体大小是10个节点的状态信息约1kb。
那定期的频率是什么样的?
redis集群内节点,每秒都在发ping消息。规律如下
(1)每秒会随机选取5个节点,找出最久没有通信的节点发送ping消息
(2)每100毫秒(1秒10次)都会扫描本地节点列表,如果发现节点最近一次接受pong消息的时间大于cluster-node-timeout/2 则立刻发送ping消息
因此,每秒单节点发出ping消息数量为
数量=1+10num(node.pong_received>cluster_node_timeout/2)
200-15/25=162.5 x (2kb+0.1kb)=341.25Kb/node x 200 = 68250Kb = 66.65Mb一个总结点数为200的Redis集群,部署在20台物理机上每台划分10个节点,cluster-node-time=15s默认,pingpong带宽高达25Mb。如果cluster-node-time=20s,pingpong带宽消耗低于15Mb。
(1) 如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
如上所述,在消息头中,最占空间的是myslots[CLUSTER_SLOTS/8]。
当槽位为65536时,这块的大小是:
65536÷8÷1024=8kb
因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
(2) redis的集群主节点数量基本不可能超过1000个。
如上所述,集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。
那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
(3) 槽位越小,节点少的情况下,压缩比高
Redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。
如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。ps:文件压缩率指的是,文件压缩前后的大小比。
-
5.3.6.2 Key是如何Sharding的?
哈希分区的基本思路是:对数据的特征值(如key)进行哈希,然后根据哈希值决定数据落在哪个节点。常见的哈希分区包括:哈希取余分区、一致性哈希分区、带虚拟节点的一致性哈希分区等。
衡量数据分区方法好坏的标准有很多,其中比较重要的两个因素是(1)数据分布是否均匀(2)增加或删减节点对数据分布的影响。由于哈希的随机性,哈希分区基本可以保证数据分布均匀;因此在比较哈希分区方案时,重点要看增减节点对数据分布的影响。
三种方案:
- 哈希取余分区
哈希取余分区思路非常简单:计算key的hash值,然后对节点数量进行取余,从而决定数据映射到哪个节点上。该方案最大的问题是,当新增或删减节点时,节点数量发生变化,系统中所有的数据都需要重新计算映射关系,引发大规模数据迁移。 - 一致性哈希分区
一致性哈希算法将整个哈希值空间组织成一个虚拟的圆环,如下图所示,范围为0-2^32-1;对于每个数据,根据key计算hash值,确定数据在环上的位置,然后从此位置沿环顺时针行走,找到的第一台服务器就是其应该映射到的服务器。 - 虚拟节点一致性哈希分区
通过增加虚拟节点的方式,使ABC三个节点在圆环上的位置更加均匀,平均了落在每一个节点上的概率。这样一来就解决了上文提到的数据存储存在不均匀的问题了,这就是一致性哈希的虚拟节点机制。
- 哈希取余分区
-
5.3.6.3 什么是一致性哈希算法?如何解决哈希不均衡?Redis用的是什么算法?
哈希算法是对master实例数量来取模,而一致性哈希则是对2^32取模,也就是值的范围在[0, 2^32 -1]。一致性哈希将其范围抽象成了一个圆环,使用CRC16算法计算出来的哈希值会落到圆环上的某个地方。
假设我们有A、B、C三个Redis实例按照如图所示的位置分布在圆环上,此时计算出来的hash值,取模之后位置落在了位置D,那么我们按照顺时针的顺序,就能够找到我们这个key应该分配的Redis实例B。同理如果我们计算出来位置在E,那么对应选择的Redis的实例就是A。
即使这个时候Redis实例B挂了,也不会影响到实例A和C的缓存。
例如此时节点B挂了,那之前计算出来在位置D的key,此时会按照顺时针的顺序,找到节点C。相当于自动的把原来节点B的流量给转移到了节点C上去。而其他原本就在节点A和节点C的数据则完全不受影响。
这就是一致性哈希,能够在我们后续需要新增节点或者删除节点的时候,不影响其他节点的正常运行。
-
5.3.6.4 Redis用的是什么哈希算法?
上面提到过,Redis Cluster采用的是类一致性哈希算法,之所以是类一致性哈希算法是因为它们实现的方式还略微有差别。
例如一致性哈希是对2^32取模,而Redis Cluster则是对2^14(也就是16384)取模。Redis Cluster将自己分成了16384个Slot(槽位)。通过CRC16算法计算出来的哈希值会跟16384取模,取模之后得到的值就是对应的槽位,然后每个Redis节点都会负责处理一部分的槽位,就像下表这样。
每个Redis实例会自己维护一份slot - Redis节点的映射关系,假设你在节点A上设置了某个key,但是这个key通过CRC16计算出来的槽位是由节点B维护的,那么就会提示你需要去节点B上进行操作。
CRC16,就是把需要校验的数据与多项式进行循环异或(XOR)
计算法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32unsigned int calccrc(unsigned char crcbuf, unsigned int crc)
{
unsigned char i;
crc = crc ^ crcbuf;
for (i = 0; i < 8; i++)
{
unsigned char chk;
chk = crc & 1;
crc = crc >> 1;
crc = crc & 0x7fff;
if (chk == 1) crc = crc ^ 0xa001;
crc = crc & 0xffff;
}
return crc;
}
unsigned int chkcrc(unsigned char *buf, unsigned char len)
{
unsigned char hi, lo;
unsigned int i;
unsigned int crc;
crc = 0xFFFF;
for (i = 0; i < len; i++)
{
crc = calccrc(*buf, crc);
buf++;
}
hi = crc % 256;
lo = crc / 256;
crc = (hi << 8) | lo;
return crc;
}查表法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64// 逆序CRC表
unsigned char aucCRCHi[]{
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40
};
unsigned char aucCRCLo[]{
0x00, 0xC0, 0xC1, 0x01, 0xC3, 0x03, 0x02, 0xC2, 0xC6, 0x06, 0x07, 0xC7,
0x05, 0xC5, 0xC4, 0x04, 0xCC, 0x0C, 0x0D, 0xCD, 0x0F, 0xCF, 0xCE, 0x0E,
0x0A, 0xCA, 0xCB, 0x0B, 0xC9, 0x09, 0x08, 0xC8, 0xD8, 0x18, 0x19, 0xD9,
0x1B, 0xDB, 0xDA, 0x1A, 0x1E, 0xDE, 0xDF, 0x1F, 0xDD, 0x1D, 0x1C, 0xDC,
0x14, 0xD4, 0xD5, 0x15, 0xD7, 0x17, 0x16, 0xD6, 0xD2, 0x12, 0x13, 0xD3,
0x11, 0xD1, 0xD0, 0x10, 0xF0, 0x30, 0x31, 0xF1, 0x33, 0xF3, 0xF2, 0x32,
0x36, 0xF6, 0xF7, 0x37, 0xF5, 0x35, 0x34, 0xF4, 0x3C, 0xFC, 0xFD, 0x3D,
0xFF, 0x3F, 0x3E, 0xFE, 0xFA, 0x3A, 0x3B, 0xFB, 0x39, 0xF9, 0xF8, 0x38,
0x28, 0xE8, 0xE9, 0x29, 0xEB, 0x2B, 0x2A, 0xEA, 0xEE, 0x2E, 0x2F, 0xEF,
0x2D, 0xED, 0xEC, 0x2C, 0xE4, 0x24, 0x25, 0xE5, 0x27, 0xE7, 0xE6, 0x26,
0x22, 0xE2, 0xE3, 0x23, 0xE1, 0x21, 0x20, 0xE0, 0xA0, 0x60, 0x61, 0xA1,
0x63, 0xA3, 0xA2, 0x62, 0x66, 0xA6, 0xA7, 0x67, 0xA5, 0x65, 0x64, 0xA4,
0x6C, 0xAC, 0xAD, 0x6D, 0xAF, 0x6F, 0x6E, 0xAE, 0xAA, 0x6A, 0x6B, 0xAB,
0x69, 0xA9, 0xA8, 0x68, 0x78, 0xB8, 0xB9, 0x79, 0xBB, 0x7B, 0x7A, 0xBA,
0xBE, 0x7E, 0x7F, 0xBF, 0x7D, 0xBD, 0xBC, 0x7C, 0xB4, 0x74, 0x75, 0xB5,
0x77, 0xB7, 0xB6, 0x76, 0x72, 0xB2, 0xB3, 0x73, 0xB1, 0x71, 0x70, 0xB0,
0x50, 0x90, 0x91, 0x51, 0x93, 0x53, 0x52, 0x92, 0x96, 0x56, 0x57, 0x97,
0x55, 0x95, 0x94, 0x54, 0x9C, 0x5C, 0x5D, 0x9D, 0x5F, 0x9F, 0x9E, 0x5E,
0x5A, 0x9A, 0x9B, 0x5B, 0x99, 0x59, 0x58, 0x98, 0x88, 0x48, 0x49, 0x89,
0x4B, 0x8B, 0x8A, 0x4A, 0x4E, 0x8E, 0x8F, 0x4F, 0x8D, 0x4D, 0x4C, 0x8C,
0x44, 0x84, 0x85, 0x45, 0x87, 0x47, 0x46, 0x86, 0x82, 0x42, 0x43, 0x83,
0x41, 0x81, 0x80, 0x40
};
unsigned short GetQuickCRC16(unsigned char * pBuffer, int Length)
{
unsigned char CRCHi = 0xFF;
unsigned char CRCLo = 0xFF;
unsigned char iIndex = 0;
for (int i = 0; i < Length; i++)
{
iIndex = CRCHi ^ pBuffer[i];
CRCHi = CRCLo ^ aucCRCHi[iIndex];
CRCLo = aucCRCLo[iIndex];
}
return (unsigned int)( CRCHi << 8 | CRCLo);// CRC校验返回值
} -
5.3.6.5 Redis为什么用CRC不用MD5/checksum?
可能MD5、SHA都是128位的,用于加密或者校验,CRC形式灵活。
-
5.3.6.6 Redis Cluster 怎么保证高可用?
参考[40]。
- 故障转移,当一个Master被其他Master判定为客观下线后,Master发起投票,选出故障Master的Slave之一作为新Master,Slave执行slaveof no one成为新Master并发出pong。
-
5.3.6.7 Redis Cluster 使用起来有什么需要注意的?
-
5.3.6.8 Redis Cluster有什么限制?
由于集群中的数据分布在不同节点中,导致一些功能受限,包括:
- key批量操作受限:例如mget、mset操作,只有当操作的key都位于一个槽时,才能进行。针对该问题,一种思路是在客户端记录槽与key的信息,每次针对特定槽执行mget/mset;另外一种思路是使用Hash Tag,将在下一小节介绍。
- keys/flushall等操作:keys/flushall等操作可以在任一节点执行,但是结果只针对当前节点,例如keys操作只返回当前节点的所有键。针对该问题,可以在客户端使用cluster nodes获取所有节点信息,并对其中的所有主节点执行keys/flushall等操作。
- 事务/Lua脚本:集群支持事务及Lua脚本,但前提条件是所涉及的key必须在同一个节点。Hash Tag可以解决该问题。
- 数据库:单机Redis节点可以支持16个数据库[41],集群模式下只支持一个,即db0。
- 复制结构:只支持一层复制结构,不支持嵌套。
- key是数据分区的最小粒度:不支持bigkey分区
-
5.3.6.8.1 Redis的数据库是什么概念?
关系型数据库多个库常用于存储不同应用程序的数据 ,且没有方式可以同时清空实例下的所有库数据。所以对于Redis来说这些db更像是一种命名空间,且不适宜存储不同应用程序的数据。比如可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库B应用的数据,不同的应用应该使用不同的Redis实例存储数据。Redis非常轻量级,一个空Redis实例占用的内在只有1M左右,所以不用担心多个Redis实例会额外占用很多内存。
-
5.3.6.8.2 什么是Hash Tag?
Hash Tag原理是:当一个key包含 {} 的时候,不对整个key做hash,而仅对 {} 包括的字符串做hash。
Hash Tag可以让不同的key拥有相同的hash值,从而分配在同一个槽里;这样针对不同key的批量操作(mget/mset等),以及事务、Lua脚本等都可以支持。不过Hash Tag可能会带来数据分配不均的问题,这时需要:(1)调整不同节点中槽的数量,使数据分布尽量均匀;(2)避免对热点数据使用Hash Tag,导致请求分布不均。
-
5.3.6.9 Redis Cluster如何通信的?
两个端口
在哨兵系统中,节点分为数据节点和哨兵节点:前者存储数据,后者实现额外的控制功能。在集群中,没有数据节点与非数据节点之分:所有的节点都存储数据,也都参与集群状态的维护。为此,集群中的每个节点,都提供了两个TCP端口:- 普通端口:即我们在前面指定的端口(7000等)。普通端口主要用于为客户端提供服务(与单机节点类似);但在节点间数据迁移时也会使用。
- 集群端口:端口号是普通端口+10000(10000是固定值,无法改变),如7000节点的集群端口为17000。集群端口只用于节点之间的通信,如搭建集群、增减节点、故障转移等操作时节点间的通信;不要使用客户端连接集群接口。为了保证集群可以正常工作,在配置防火墙时,要同时开启普通端口和集群端口。
Gossip协议
节点间通信,按照通信协议可以分为几种类型:单对单、广播、Gossip协议等。重点是广播和Gossip的对比。广播是指向集群内所有节点发送消息;优点是集群的收敛速度快(集群收敛是指集群内所有节点获得的集群信息是一致的),缺点是每条消息都要发送给所有节点,CPU、带宽等消耗较大。
Gossip协议的特点是:在节点数量有限的网络中,每个节点都“随机”的与部分节点通信(并不是真正的随机,而是根据特定的规则选择通信的节点),经过一番杂乱无章的通信,每个节点的状态很快会达到一致。Gossip协议的优点有负载(比广播)低、去中心化、容错性高(因为通信有冗余)等;缺点主要是集群的收敛速度慢。
消息类型
集群中的节点采用固定频率(每秒10次)的定时任务进行通信相关的工作:判断是否需要发送消息及消息类型、确定接收节点、发送消息等。如果集群状态发生了变化,如增减节点、槽状态变更,通过节点间的通信,所有节点会很快得知整个集群的状态,使集群收敛。节点间发送的消息主要分为5种:meet消息、ping消息、pong消息、fail消息、publish消息。不同的消息类型,通信协议、发送的频率和时机、接收节点的选择等是不同的。
- MEET消息:在节点握手阶段,当节点收到客户端的CLUSTER MEET命令时,会向新加入的节点发送MEET消息,请求新节点加入到当前集群;新节点收到MEET消息后会回复一个PONG消息。
- PING消息:集群里每个节点每秒钟会选择部分节点发送PING消息,接收者收到消息后会回复一个PONG消息。PING消息的内容是自身节点和部分其他节点的状态信息;作用是彼此交换信息,以及检测节点是否在线。PING消息使用Gossip协议发送,接收节点的选择兼顾了收敛速度和带宽成本,具体规则如下:(1)随机找5个节点,在其中选择最久没有通信的1个节点(2)扫描节点列表,选择最近一次收到PONG消息时间大于cluster_node_timeout/2的所有节点,防止这些节点长时间未更新。
- PONG消息:PONG消息封装了自身状态数据。可以分为两种:第一种是在接到MEET/PING消息后回复的PONG消息;第二种是指节点向集群广播PONG消息,这样其他节点可以获知该节点的最新信息,例如故障恢复后新的主节点会广播PONG消息。
- FAIL消息:当一个主节点判断另一个主节点进入FAIL状态时,会向集群广播这一FAIL消息;接收节点会将这一FAIL消息保存起来,便于后续的判断。
- PUBLISH消息:节点收到PUBLISH命令后,会先执行该命令,然后向集群广播这一消息,接收节点也会执行该PUBLISH命令。
-
5.3.6.10 redis cluster的参数如何配置?
cluster_node_timeout
cluster_node_timeout参数在前面已经初步介绍;它的默认值是15s,影响包括:- 影响PING消息接收节点的选择:值越大对延迟容忍度越高,选择的接收节点越少,可以降低带宽,但会降低收敛速度;应根据带宽情况和应用要求进行调整。
- 影响故障转移的判定和时间:值越大,越不容易误判,但完成转移消耗时间越长;应根据网络状况和应用要求进行调整。
cluster-require-full-coverage
前面提到,只有当16384个槽全部分配完毕时,集群才能上线。这样做是为了保证集群的完整性,但同时也带来了新的问题:当主节点发生故障而故障转移尚未完成,原主节点中的槽不在任何节点中,此时会集群处于下线状态,无法响应客户端的请求。
cluster-require-full-coverage参数可以改变这一设定:如果设置为no,则当槽没有完全分配时,集群仍可以上线。参数默认值为yes,如果应用对可用性要求较高,可以修改为no,但需要自己保证槽全部分配。 -
5.3.6.11 用过redis-trib.rb吗?
-
5.3.6.12 Redis的选举流程?
1
2
3
4
5
6
7
8Node1 Node2 Node3
| | |
timeout | |
X----RequestVote---->| |
X--------------------|-----RequestVote---->|
|<-------vote--------X |
|<-------vote--------|-------------- ------X
become leader | | -
5.3.6.13 常用的选举算法
-
5.3.7 如果Redis挂了怎么吗?数据会丢失吗?说说Redis是提供了哪些高可用方案?
- 持久化机制。AOF(Append Only File) 和 RDB (Redis Database)。
- 主从复制。
- 哨兵。Sentinel。
- Cluster。
[43]
-
5.3.7.1 具体讲讲持久化两个方案的原理和具体机制,以及如何配置?
[44]
RDB全量和AOF增量
RBD:
定时fork执行全量导出。- cron每100ms检测,满足save m n,n次变化in m秒。
- 如果达成,主进程fork,此时阻塞,fork后恢复
- 子进程根据主进程内存快照生成RDB文件,写入磁盘完成原子替换。
1
[REDIS][DB_VERSION][SELECTDB][0][pairs][SELECTDB][3][pairs][EOF][checksum]AOF:
实时写出写命令,定时flush落盘。- 命令追加(append):将Redis的写命令追加到缓冲区aof_buf;
- 文件写入(write)和文件同步(sync):根据不同的同步策略将aof_buf中的内容同步到硬盘;
- 文件重写(rewrite):定期重写AOF文件,达到压缩的目的。
appendfsync always[always] no[30s] everysec[1s]
-
5.3.7.2 讲讲哨兵Sentinel机制?
[45]
通过一个sentinel集群监控master节点,sentinel集群内的节点是无状态等价的,并持有相同的元信息。- 定时任务:每个哨兵节点维护了3个定时任务。定时任务的功能分别如下:通过向主从节点发送info命令获取最新的主从结构;通过发布订阅功能获取其他哨兵节点的信息;通过向其他节点发送ping命令进行心跳检测,判断是否下线。
- 主观下线:哨兵节点在对主节点进行主观下线后,会通过sentinel is-master-down-by-addr命令询问其他哨兵节点该主节点的状态;如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。
- 客观下线:哨兵节点在对主节点进行主观下线后,会通过sentinel is-master-down-by-addr命令询问其他哨兵节点该主节点的状态;如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
- 选举领导者哨兵节点:当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个领导者哨兵节点,并由该领导者节点对其进行故障转移操作。监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。选举的具体过程这里不做详细描述,一般来说,哨兵选择的过程很快,谁先完成客观下线,一般就能成为领导者。
- 故障转移:选举出的领导者哨兵,开始进行故障转移操作,该操作大体可以分为3个步骤:
- 在从节点中选择新的主节点:选择的原则是,首先过滤掉不健康的从节点;然后选择优先级最高的从节点(由slave-priority指定);如果优先级无法区分,则选择复制偏移量最大的从节点;如果仍无法区分,则选择runid最小的从节点。
- 更新主从状态:通过slaveof no one命令,让选出来的从节点成为主节点;并通过slaveof命令让其他节点成为其从节点。
- 将已经下线的主节点(即6379)设置为新的主节点的从节点,当6379重新上线后,它会成为新的主节点的从节点。
-
5.3.7.2.1 实际配置sentinel有哪些坑?
- 哨兵节点的数量应不止一个,一方面增加哨兵节点的冗余,避免哨兵本身成为高可用的瓶颈;另一方面减少对下线的误判。此外,这些不同的哨兵节点应部署在不同的物理机上。
- 哨兵节点的数量应该是奇数,便于哨兵通过投票做出“决策”:领导者选举的决策、客观下线的决策等。
- 各个哨兵节点的配置应一致,包括硬件、参数等;此外,所有节点都应该使用ntp或类似服务,保证时间准确、一致。
- 哨兵的配置提供者和通知客户端功能,需要客户端的支持才能实现,如前文所说的Jedis;如果开发者使用的库未提供相应支持,则可能需要开发者自己实现。
- 当哨兵系统中的节点在docker(或其他可能进行端口映射的软件)中部署时,应特别注意端口映射可能会导致哨兵系统无法正常工作,因为哨兵的工作基于与其他节点的通信,而docker的端口映射可能导致哨兵无法连接到其他节点。例如,哨兵之间互相发现,依赖于它们对外宣称的IP和port,如果某个哨兵A部署在做了端口映射的docker中,那么其他哨兵使用A宣称的port无法连接到A。
-
5.3.7.3 Redis是怎么主从复制的?
连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段
连接建立阶段
从节点发起连接请求。
数据同步阶段
主从节点之间的连接建立以后,便可以开始进行数据同步,该阶段可以理解为从节点数据的初始化。具体执行的方式是:从节点向主节点发送psync命令(Redis2.8以前是sync命令),开始同步。数据同步阶段是主从复制最核心的阶段,根据主从节点当前状态的不同,可以分为全量复制和部分复制,下面会有一章专门讲解这两种复制方式以及psync命令的执行过程,这里不再详述。
需要注意的是,在数据同步阶段之前,从节点是主节点的客户端,主节点不是从节点的客户端;而到了这一阶段及以后,主从节点互为客户端。原因在于:在此之前,主节点只需要响应从节点的请求即可,不需要主动发请求,而在数据同步阶段和后面的命令传播阶段,主节点需要主动向从节点发送请求(如推送缓冲区中的写命令),才能完成复制。
2.8之前是全量复制
- 主节点通过bgsave命令fork子进程进行RDB持久化,该过程是非常消耗CPU、内存(页表复制)、硬盘IO的;关于bgsave的性能问题,可以参考 深入学习Redis(2):持久化
- 主节点通过网络将RDB文件发送给从节点,对主从节点的带宽都会带来很大的消耗
- 从节点清空老数据、载入新RDB文件的过程是阻塞的,无法响应客户端的命令;如果从节点执行bgrewriteaof,也会带来额外的消耗
之后引入部分复制
-
复制偏移量
主节点和从节点分别维护一个复制偏移量(offset),代表的是主节点向从节点传递的字节数;主节点每次向从节点传播N个字节数据时,主节点的offset增加N;从节点每次收到主节点传来的N个字节数据时,从节点的offset增加N。offset用于判断主从节点的数据库状态是否一致:如果二者offset相同,则一致;如果offset不同,则不一致,此时可以根据两个offset找出从节点缺少的那部分数据。例如,如果主节点的offset是1000,而从节点的offset是500,那么部分复制就需要将offset为501-1000的数据传递给从节点。而offset为501-1000的数据存储的位置,就是下面要介绍的复制积压缓冲区。
-
复制积压缓冲区
复制积压缓冲区
复制积压缓冲区是由主节点维护的、固定长度的、先进先出(FIFO)队列,默认大小1MB;当主节点开始有从节点时创建,其作用是备份主节点最近发送给从节点的数据。注意,无论主节点有一个还是多个从节点,都只需要一个复制积压缓冲区。在命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset)。由于复制积压缓冲区定长且是先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。
由于该缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置repl-backlog-size);例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
从节点将offset发送给主节点后,主节点根据offset和缓冲区大小决定能否执行部分复制:
- 如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制;
- 如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
-
服务器运行ID(runid)
每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。通过info Server命令,可以查看节点的runid:
redis-cli info server | grep runid
主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制:- 如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况);
- 如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
命令传播阶段
数据同步阶段完成后,主从节点进入命令传播阶段;在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据的一致性。在命令传播阶段,除了发送写命令,主从节点还维持着心跳机制:PING和REPLCONF ACK。由于心跳机制的原理涉及部分复制,因此将在介绍了部分复制的相关内容后单独介绍该心跳机制。
需要注意的是,命令传播是异步的过程,即主节点发送写命令后并不会等待从节点的回复;因此实际上主从节点之间很难保持实时的一致性,延迟在所难免。数据不一致的程度,与主从节点之间的网络状况、主节点写命令的执行频率、以及主节点中的repl-disable-tcp-nodelay配置等有关。
repl-disable-tcp-nodelay no:该配置作用于命令传播阶段,控制主节点是否禁止与从节点的TCP_NODELAY;默认no,即不禁止TCP_NODELAY。当设置为yes时,TCP会对包进行合并从而减少带宽,但是发送的频率会降低,从节点数据延迟增加,一致性变差;具体发送频率与Linux内核的配置有关,默认配置为40ms。当设置为no时,TCP会立马将主节点的数据发送给从节点,带宽增加但延迟变小。
一般来说,只有当应用对Redis数据不一致的容忍度较高,且主从节点之间网络状况不好时,才会设置为yes;多数情况使用默认值no。
1) 主从节点彼此都有心跳检测机制, 各自模拟成对方的客户端进行通信, 通过client list命令查看复制相关客户端信息, 主节点的连接状态为flags=M, 从节点连接状态为flags=S。
2) 主节点默认每隔10秒对从节点发送ping命令, 判断从节点的存活性和连接状态。 可通过参数repl-ping-slave-period控制发送频率。
3) 从节点在主线程中每隔1秒发送replconf ack{offset}命令, 给主节点上报自身当前的复制偏移量。 -
5.3.8 如何排查redis的性能问题?
Fork阻塞
在Redis的实践中,众多因素限制了Redis单机的内存不能过大,例如:- 当面对请求的暴增,需要从库扩容时,Redis内存过大会导致扩容时间太长;
- 当主机宕机时,切换主机后需要挂载从库,Redis内存过大导致挂载速度过慢;
- 以及持久化过程中的fork操作,下面详细说明。
父进程通过fork操作可以创建子进程;子进程创建后,父子进程共享代码段,不共享进程的数据空间,但是子进程会获得父进程的数据空间的副本。在操作系统fork的实际实现中,基本都采用了写时复制技术,即在父/子进程试图修改数据空间之前,父子进程实际上共享数据空间;但是当父/子进程的任何一个试图修改数据空间时,操作系统会为修改的那一部分(内存的一页)制作一个副本。
虽然fork时,子进程不会复制父进程的数据空间,但是会复制内存页表(页表相当于内存的索引、目录);父进程的数据空间越大,内存页表越大,fork时复制耗时也会越多。
在Redis中,无论是RDB持久化的bgsave,还是AOF重写的bgrewriteaof,都需要fork出子进程来进行操作。如果Redis内存过大,会导致fork操作时复制内存页表耗时过多;而Redis主进程在进行fork时,是完全阻塞的,也就意味着无法响应客户端的请求,会造成请求延迟过大。
对于不同的硬件、不同的操作系统,fork操作的耗时会有所差别,一般来说,如果Redis单机内存达到了10GB,fork时耗时可能会达到百毫秒级别(如果使用Xen虚拟机,这个耗时可能达到秒级别)。因此,一般来说Redis单机内存一般要限制在10GB以内;不过这个数据并不是绝对的,可以通过观察线上环境fork的耗时来进行调整。观察的方法如下:执行命令info stats,查看latest_fork_usec的值,单位为微秒。
为了减轻fork操作带来的阻塞问题,除了控制Redis单机内存的大小以外,还可以适度放宽AOF重写的触发条件、选用物理机或高效支持fork操作的虚拟化技术等,例如使用Vmware或KVM虚拟机,不要使用Xen虚拟机。
AOF追加阻塞
前面提到过,在AOF中,如果AOF缓冲区的文件同步策略为everysec,则:在主线程中,命令写入aof_buf后调用系统write操作,write完成后主线程返回;fsync同步文件操作由专门的文件同步线程每秒调用一次。这种做法的问题在于,如果硬盘负载过高,那么fsync操作可能会超过1s;如果Redis主线程持续高速向aof_buf写入命令,硬盘的负载可能会越来越大,IO资源消耗更快;如果此时Redis进程异常退出,丢失的数据也会越来越多,可能远超过1s。
为此,Redis的处理策略是这样的:主线程每次进行AOF会对比上次fsync成功的时间;如果距上次不到2s,主线程直接返回;如果超过2s,则主线程阻塞直到fsync同步完成。因此,如果系统硬盘负载过大导致fsync速度太慢,会导致Redis主线程的阻塞;此外,使用everysec配置,AOF最多可能丢失2s的数据,而不是1s。
AOF追加阻塞问题定位的方法:
(1)监控info Persistence中的aof_delayed_fsync:当AOF追加阻塞发生时(即主线程等待fsync而阻塞),该指标累加。
(2)AOF阻塞时的Redis日志:
Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.
(3)如果AOF追加阻塞频繁发生,说明系统的硬盘负载太大;可以考虑更换IO速度更快的硬盘,或者通过IO监控分析工具对系统的IO负载进行分析,如iostat(系统级io)、iotop(io版的top)、pidstat等。
内存碎片
mem_fragmentation_ratio一般大于1,且该值越大,内存碎片比例越大。mem_fragmentation_ratio<1,说明Redis使用了虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。 -
5.3.9 如何优化redis的性能?
- 持久化,fork和aof阻塞
- 网络,gossip协议timeout的超时改大,降低带宽占用
-
5.3.10 redis的内存是越大越好吗?
在 深入学习Redis(2):持久化 一文中,讲到了fork操作对Redis单机内存大小的限制。实际上在Redis的使用中,限制单机内存大小的因素非常之多,下面总结一下在主从复制中,单机内存过大可能造成的影响:
- 切主:当主节点宕机时,一种常见的容灾策略是将其中一个从节点提升为主节点,并将其他从节点挂载到新的主节点上,此时这些从节点只能进行全量复制;如果Redis单机内存达到10GB,一个从节点的同步时间在几分钟的级别;如果从节点较多,恢复的速度会更慢。如果系统的读负载很高,而这段时间从节点无法提供服务,会对系统造成很大的压力。
- 从库扩容:如果访问量突然增大,此时希望增加从节点分担读负载,如果数据量过大,从节点同步太慢,难以及时应对访问量的暴增。
- 缓冲区溢出:(1)和(2)都是从节点可以正常同步的情形(虽然慢),但是如果数据量过大,导致全量复制阶段主节点的复制缓冲区溢出,从而导致复制中断,则主从节点的数据同步会全量复制->复制缓冲区溢出导致复制中断->重连->全量复制->复制缓冲区溢出导致复制中断……的循环。
- 超时:如果数据量过大,全量复制阶段主节点fork+保存RDB文件耗时过大,从节点长时间接收不到数据触发超时,主从节点的数据同步同样可能陷入全量复制->超时导致复制中断->重连->全量复制->超时导致复制中断……的循环。
此外,主节点单机内存除了绝对量不能太大,其占用主机内存的比例也不应过大:最好只使用50%-65%的内存,留下30%-45%的内存用于执行bgsave命令和创建复制缓冲区等。
-
6 Kafka 是你们自己搭的吗?是怎么配置的?
-
6.1 Kafka为什么这么快?
- 分Partition并行处理。kafka中的topic中的内容可以被分为多分区存在,每个分区又分为多个段,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力。
- 顺序写入磁盘。kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能,顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写。对于SSD而言,同样也是顺序读写速度高于随机读写。
- Page Cache,减少写磁盘次数。
- 压缩,减少传输的数据量。。
- 批量发送。
- 零拷贝。利用Linux kernel"零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”。
-
6.2 Kafka 怎么扩容?需要做什么处理?
[47]扩容Broker。在扩容之前就已经存在的topic并不会自动地分配分区到新节点上。
增加分区:1
./bin/kafka-topics.sh –zookeeper ip:host,ip:host,ip:host –alter –partitions 5 –topic XXX(topic)重新分区:kafka-reassign-partitions.sh
- generate模式,给定需要重新分配的topic,自动生成reassign plan(只是生成,并不执行)
- execute模式,根据指定的reassign plan重新分配Partition
- verify模式,验证重新分配Partition是否成功
- topics-to-move.json
1
2
3
4{"topics": [{"topic": "topic1"},
{"topic": "topic2"}],
"version":1
}- 生成partition分配表
1
./kafka-reassign-partitions --zookeeper ${zk_address} --topics-to-move-json-file topic-to-move.json --broker-list "140,141" --generate1
2
3
4
5
6
7Current partition replica assignment
{"version":1,"partitions":[{"topic":"testTopic","partition":1,"replicas":[61,62]},{"topic":"testTopic","partition":0,"replicas":[62,61]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"testTopic","partition":1,"replicas":[140,141]},{"topic":"testTopic","partition":0,"replicas":[141,140]}]}- 执行迁移
1
./kafka-reassign-partitions --zookeeper ${zk_address} --reassignment-json-file expand-cluster-reassignment.json --execute- 查看迁移进度
1
./kafka-reassign-partitions --zookeeper ${zk_address} --reassignment-json-file expand-cluster-reassignment.json --verify -
6.3 Partition越多越好吗?为什么?
-
越多的partition可以提供更高的吞吐量,但是网络IO资源受限于Broker。
-
越多的分区需要打开更多的文件句柄。
在kafka的数据日志文件目录中,每个日志数据段都会分配两个文件,一个索引文件和一个数据文件。因此,随着partition的增多,需要的文件句柄数急剧增加,必要时需要调整操作系统允许打开的文件句柄数。 -
更多的分区会导致端对端的延迟
kafka端对端的延迟为producer端发布消息到consumer端消费消息所需的时间,即consumer接收消息的时间减去produce发布消息的时间。kafka在消息正确接收后才会暴露给消费者,即在保证in-sync副本复制成功之后才会暴露,瓶颈则来自于此。在一个broker上的副本从其他broker的leader上复制数据的时候只会开启一个线程,假设partition数量为n,每个副本同步的时间为1ms,那in-sync操作完成所需的时间即n*1ms,若n为10000,则需要10秒才能返回同步状态,数据才能暴露给消费者,这就导致了较大的端对端的延迟。 -
越多的partition意味着需要更多的内存
在新版本的kafka中可以支持批量提交和批量消费,而设置了批量提交和批量消费后,每个partition都会需要一定的内存空间。假设为100k,当partition为100时,producer端和consumer端都需要10M的内存;当partition为100000时,producer端和consumer端则都需要10G内存。无限的partition数量很快就会占据大量的内存,造成性能瓶颈。 -
越多的partition会导致更长时间的恢复期,降低高可用性
kafka通过多副本复制技术,实现kafka的高可用性和稳定性。每个partition都会有多个副本存在于多个broker中,其中一个副本为leader,其余的为follower。当kafka集群其中一个broker出现故障时,在这个broker上的leader会需要在其他broker上重新选择一个副本启动为leader,这个过程由kafka controller来完成,主要是从Zookeeper读取和修改受影响partition的一些元数据信息。通常情况下,当一个broker有计划的停机上,该broker上的partition leader会在broker停机前有次序的一一移走,假设移走一个需要1ms,10个partition leader则需要10ms,这影响很小,并且在移动其中一个leader的时候,其他九个leader是可用的,因此实际上每个partition leader的不可用时间为1ms。但是在宕机情况下,所有的10个partition
leader同时无法使用,需要依次移走,最长的leader则需要10ms的不可用时间窗口,平均不可用时间窗口为5.5ms,假设有10000个leader在此宕机的broker上,平均的不可用时间窗口则为5.5s。
更极端的情况是,当时的broker是kafka controller所在的节点,那需要等待新的kafka leader节点在投票中产生并启用,之后新启动的kafka leader还需要从zookeeper中读取每一个partition的元数据信息用于初始化数据。在这之前partition leader的迁移一直处于等待状态。
-
如何确定分区数量呢?
可以遵循一定的步骤来尝试确定分区数:创建一个只有1个分区的topic,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位可以是MB/s。然后假设总的目标吞吐量是Tt,那么分区数 = Tt / max(Tp, Tc)
说明:Tp表示producer的吞吐量。测试producer通常是很容易的,因为它的逻辑非常简单,就是直接发送消息到Kafka就好了。Tc表示consumer的吞吐量。测试Tc通常与应用的关系更大, 因为Tc的值取决于你拿到消息之后执行什么操作,因此Tc的测试通常也要麻烦一些。
-
-
7 怎么部署的服务?
阿里云ACK集群,k8s。
-
7.1 k8s的服务结构知道?
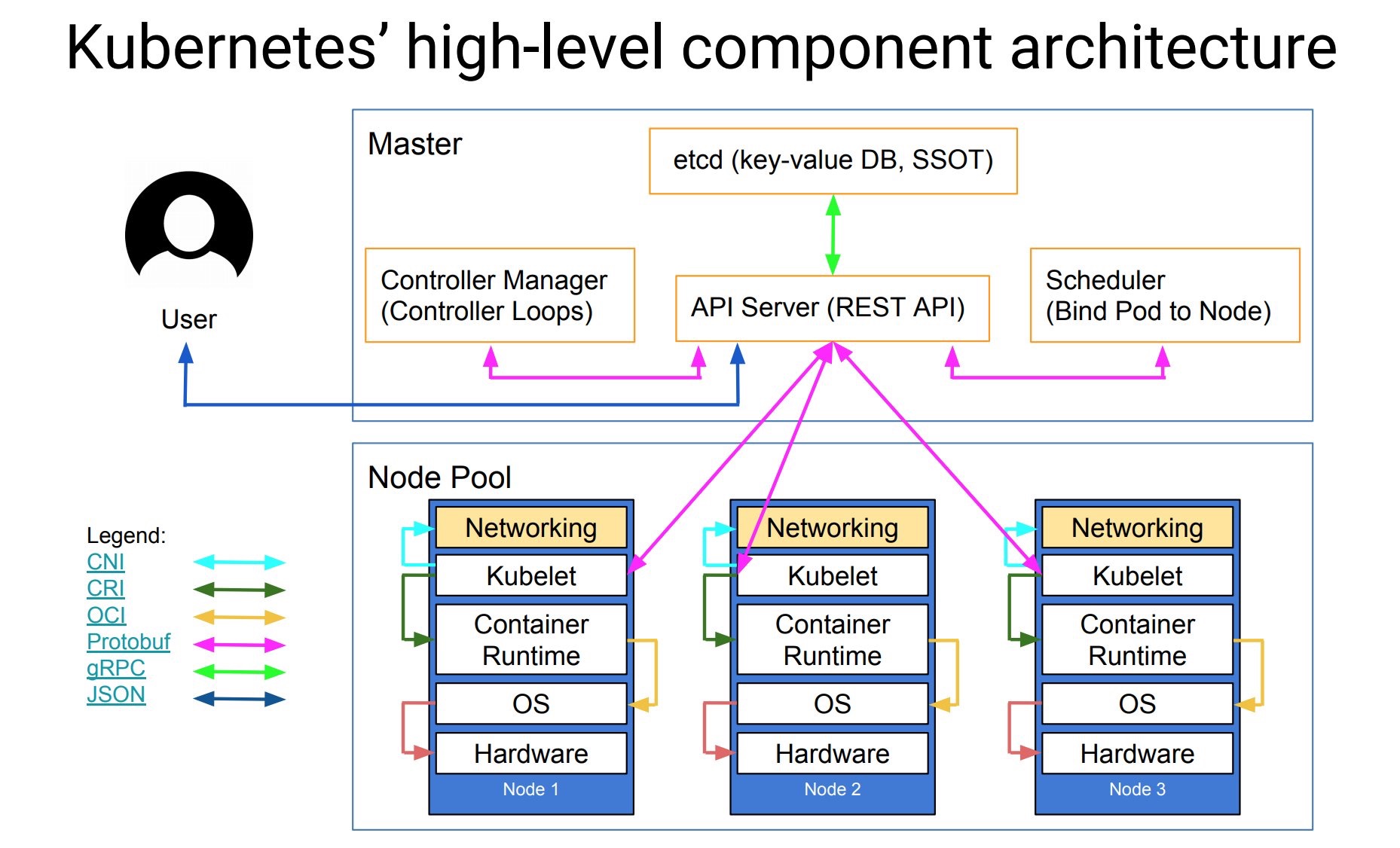
Control Plane:
- etcd 分布式KV数据库,用于保存集群状态
- api-server 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制
- scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上
- controller-manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
- cloud-controller-manager 可选,云服务商API
Node:
- kube-proxy 为 Service 提供 cluster 内部的服务发现和负载均衡
- kubelet 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理
- container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI)
Plugin:
- CoreDNS 负责为整个集群提供 DNS 服务
- Ingress Controller 为服务提供外网入口
- Prometheus 提供资源监控
- Dashboard 提供 GUI
- Federation 提供跨可用区的集群
-
7.1.1 讲讲etcd和其他kv的对比
-
7.2 StatefulSet知道吗?说说功能和原理?
用于保证一组pod的启动顺序和固定分配名称。即使挂掉后重启依然使用之前的名称,用于有状态的系统部署,如MySQL,ZooKeeper等。
使用Headless Service暴露Pod域名。 -
7.3 怎么Debug,比如系统Latency高,QPS低等,怎么排查问题?
查看节点资源利用率。如果是网络问题使用抓包软件dump,需要检查是否集群配置了规格过低的NAT,错误地使用了公网域名而不是VPC域名。
需要在预发环境下重现,并逐级排查。
可以在代码中添加tracing。-
7.3.1 怎么Tracing?
-
7.3.2 如果预发环境复现不了怎么办?
-
7.3.3 怎么测试和修复不影响线上?
-
-
7.4 什么是Headless Service? 有什么用?
[49]
有时候不需要将pod作为一组服务暴露,可以把ClusterIP设为None,这时就是Headless Service,暴露所有endpoints,不经过kube-proxy,可以直接访问pod的域名,搭配StatefulSet可以获得固定pod地址。 -
7.5 Docker Swarm 和 Kubernetes 有什么区别?
-
7.6 在k8s上部署过有状态应用吗?遇到了什么麻烦?
-
7.7 Init Container功能是什么?怎么执行的?
-
7.8 什么是Operator?功能是什么?写过吗?
-
7.9 你们用API直接控制job/server?怎们保证权限不泄露?说说RBAC?
-
7.9.1 如果worker挂了呢?要怎么处理?
使用replica set保证worker数量。同时加入prometheus监控报警。
-
7.10 什么是Ingress?怎么用的?
Proxy-Server controls routing and traffic distribution.
-
8 计量计费这块是怎么做的?怎么防止计费出错?
我们每五分钟统计一次消耗quota,并且推送到阿里云的计量计费系统,系统也是每五分钟发起出账任务,类型为实时按月重批价。
出错分几种情况:- 无法往里写入时间戳,等待并重试3次。写入时间戳和统计数量作为一个transaction,写入或统计出错会回滚。交由下个时间点合并统计。
- 向计量系统推送出错,back-off重试。
- pipeline向数据库写入,可在推送前数据手工处理。
- 可发起手工任务向计量系统推送。
-
9 怎么做的监控?
Prometheus & Grafana Alter
-
9.1 prometheus监控了什么?做了什么配置?
微服务内,使用go-prometheus的接口监控API指标,短信发送速率,发送量等,监控与报警。
ACK提供了node和pod的监控与报警。 -
10 怎么管理短信发送和算法任务的?
由统一的任务启动器启动和删除。通过k8s的API启动Job/CronJob。
-
10.1 如何监控这些启动任务的状态的?
-
11 怎么区分不同优先级和不同用户的?
我们在三个维度上区分优先级。
- 短信类型。短信类型可以分成营销、通知和验证码三类,分别对应的通道质量和要求是不一样的。营销短信的时效性通常在一天到一周左右,有可能遭到用户屏蔽。通知类短信的时效性在小时级别,验证码的时效性在分钟级别,因此这三类短信是分别用不同质量的通道账号维护的,会在API服务写入不同的Kafka Topic,每个Topic并行发送,互相独立,超时等配置略有区别,保证验证码短信的时效性和通道质量。
- 用户类型。在短信类型的维度上区分用户类型,优先保证VIP客户的发送质量,同样使用Topic区隔。
- 用户间,用户可能会出现一个用户集中发送,导致其他用户排队的情况,目前我们没有专门处理,而是使用Kafka的Key分区机制,让不同uid的客户分配到不同的Partition上去,consumer消费时尽量round robin交叉消费,缓解排队问题。如果有用户需要完全独立不受影响的通道或者更高质量的通道,我们可以增加一系列user_xxx的topic,并且用完全匹配或者正则匹配消费topic。或者在消费端增加用户Specific的Channel。
-
11.1 Kafka的Topic有数量限制吗?为什么?
超过1000个会明显影响性能。因为Kafka的每个Topic都是独立顺序写入自己的缓冲区的,因此在Topic数量越多,越碎片化,越接近随机读写。
-
12 服务节点挂了怎么处理?升级的时候怎么不影响业务?
限流,熔断,降级 Sentinel-Go控制
限流,滑动窗口和漏桶法,保护API级,短信服务级
熔断,当
降级,系统需要调用第三方服务,当第三方服务出现不稳定,超时,RT上升等, -
13 Go的基础知识
-
13.1 怎么管理go的包的,会有版本冲突问题吗?
-
13.2 go为什么这么快?
-
13.3 go的并发模型?
CSP。 CSP(communicating sequential processes)
- 并发实体,通常可以理解为执行线程,它们相互独立,且并发执行;
- 通道,并发实体之间使用通道发送信息。
-
13.3.1 go的线程模型和常见的线程模型有什么区别。
常见的线程模型是1级模型,包括1:1, 1:M,M:N。Go用的是GMP模型,两级模型。GMP分别表示Goroutine,Machine和Process,第一级是Goroutine到Process,goroutine被分配到全局队列和process的队列,第二级是Process到Machine,Machine对应操作系统的内核线程,当Machine不足时会创建新的M。
G理论上没有数量上限限制的。查看当前G的数量可以使用runtime. NumGoroutine()。
P由启动时环境变量 $GOMAXPROCS 或者是由runtime.GOMAXPROCS() 决定。这意味着在程序执行的任意时刻都只有 $GOMAXPROCS 个 goroutine 在同时运行。
M go 语言本身的限制:go 程序启动时,会设置 M 的最大数量,默认 10000. 但是内核很难支持这么多的线程数,所以这个限制可以忽略。 runtime/debug 中的 SetMaxThreads 函数,设置 M 的最大数量 一个 M 阻塞了,会创建新的 M。M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。 -
13.3.2 Linux的线程调度模型是1:1,1:M,还是M:N?
是1:1。Linux历史上经历了三个主要版本的线程模型,首先是LinuxThreads,是1:1模型,但因为LinuxThreads不符合POSIX规范并且有许多缺陷,后来IBM开发了NGPT,是M:N模型,性能比LinuxThreads高,但比较复杂。后来NPTL又出现,是1:1模型,性能更高,曾经它也想用M:N模型,但过于复杂,需要对内核进行大范围改动。[53][54]
-
13.3.3 Linux为什么区分用户态和内核态?
保护内核空间不被用户程序轻易修改。
防止用户程序执行高危指令。
区分内核空间和用户空间本质上是要提高操作系统的稳定性及可用性。 -
13.3.4 CPU怎么区分用户态和内核态?
通过CPU的特权模式和普通模式区分用户态和内核态程序。Ring0 & Ring3。用户态/内核态在CPU里是有一个状态位来记录的,CPU就是根据这个状态位来判断。保证这个状态位当且仅当在操作系统内部为内核态,是操作系统的任务。
-
13.3.5 如何从用户态进入内核态?
系统调用、软中断和硬件中断。
-
13.4 go的内存模型?
TCMalloc
-
13.4.1 tcmalloc有什么问题?有代替方案吗?
-
13.5 go的gc怎么做的?
三色标记法
-
13.6 为什么goroutine可以开很多,有数量限制吗?和线程和进程有什么区别?
goroutine是在user space的轻量级调度结构,由go runtime调度。相比之下,线程与进程是由操作系统调度,context switching的开销要大很多。
-
13.6.1 协程,线程和进程具体有什么区别?
-
13.6.2 goroutine需要协程池吗?
大部分场景下不用。
在极端压力场景下,goroutine的执行时间很长,大部分时间在runtime.findRunableG。
在限定最高并发数量的情况下。sometimes, wo don’t create a pool for goroutine but for struct, like context.
-
13.7 go怎么做错误处理,sub goroutine的panic怎么处理。
-
13.8 go有什么问题?
-
13.9 channel有什么坑?
-
13.9.1 无缓冲 chan 的发送和接收是否同步?
发送端会阻塞直到接受。
-
13.9.2 channel是怎么实现的?
环形队列加锁。Circular Queue With Mutex。
-
13.9.3 如果使用了channel,在线上升级版本的时候会不会丢失数据,怎么保证不丢失数据?
-
13.10 GOPATH 和 GOROOT 有什么区别?
-
13.11 go的逃逸分析有什么用?
-
13.12 线程安全,怎么启动多个goroutine并等待所有goroutine执行完成。
-
13.12.1 怎么加锁?
-
13.12.2 如何顺序输出?
-
13.12.3 goroutine泄露有什么成因?怎么处理?
-
13.12.4 除了mutex外还有哪些方式安全读写共享变量?
-
13.12.5 Go Testing
-
13.12.6 用的什么Web框架?
go-gin
-
13.12.6.1 gin用了什么中间件?
- 鉴权,会查询用户身份,调用阿里云鉴权服务。
- Binding, 对Path,Query,Body等做了数据绑定和检查
- Log,日志。
- Metrics for prometheus.
- 流控。rate.NewLimiter(1000, 1500) 令牌桶。
-
13.12.6.2 gin用了资源池吗?
用了sync.Pool,为何Gin使用Sync.Pool呢?到底解决框架本身什么性能瓶颈呢?
- Gin server接受requset,从context pool中取出context赋值给gin.Context
- Gin将context传入http handler开始业务逻辑处理
- 经过一系列流程后,我们可能需要以异步的方式开启goroutine继续处理业务逻辑,比如分发消息到mq等,但是这里有问题哈,我们下面会说到。
- 在流程末尾,将对象归还pool以便重用。
步骤3这里的问题主要是ctx对象无法做到复用了,这里因为context在流程末尾已经被gin回收到pool中,此时context的状态是未知的,可能被回收或者被重置后放到其他 groutine中,在异步任务中读取会引起业务错误。
解决方案:
- 在需要异步的地方copy对象
- 使用其他的pool组件或者自己实现
Gin框架因为需要给每个请求分配Context,当百万并发到来时,频繁的创建对象会给golang的GC带来非常大的压力,因此Gin作者就利用Pool技术将Context对象复用起来,这样不但可以提升性能,而且在一定程度上可以缓解GC的压力。
-
13.12.6.3 还有什么库用到了sync.Pool?
fmt, echo
-
13.13 Go怎么profiling?
-
13.14 Go的锁
-
13.14.1 有哪些无锁机制?
-
14 模型分布式训练系统,大数据系统是什么结构?怎么搭建的?知道怎么用开源方式搭建吗?
Hadoop, HBase, MapReduce, Spark
-
14.1 介绍一下Hadoop?
-
14.2 介绍一下HBase,它比PostgreSQL或者MySQL有什么优缺点?
-
14.3 流式处理怎么做的?
-
15 说说分布式事务?
-
15.1 什么是脏读(Dirty Read)、不可重复读(Non-repeatable Read)、幻读(Phantom Read)?怎么解决?
-
15.2 什么CAP?怎么理解?
-
15.3 什么是MVCC?
Multi-Version Concurrency Control[56],多版本并发控制,用于在READ COMMITTED和REPEATABLE READ两个隔离级别下实现读写并发。而READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。SERIALIZABLE则会对所有读取的行都加锁。
READ COMMITTED和REPEATABLE READ使用MVCC并行事务。
-
15.3.1 MVCC的实现原理?
基于事务并发和一致性。Undo Log和Read View。
-
15.3.2 什么是ACID?
A: Atomic When a transaction starts, either do all operations or none.
C: Consistency Correctness, A -> B must have the same result.
I: Isolation One transaction at a time.
D: Durability After transcation being executed, all updates are saved into db, cannot roll back. -
15.3.3 什么是事务隔离级别?
| Level | Dirty Read | Unrepeatable Read | Phantom Read |
|---|---|---|---|
| Serializable | Y | Y | Y |
| Repeatable Read | N | Y | Y |
| Read Committed | N | N | Y |
| Read Uncommitted | N | N | N |
-
15.3.4 MVCC解决了幻读问题吗?
总结一下就是,MVCC解决了幻读的问题吗?严谨来说并没有解决,MVCC利用版本链,undo log,Read View可以在快照读模式下解决幻读问题,并且不用加锁解决读写冲突问题,极大的增加了数据库的并发量。另一方面,在当前读的模式下,仅仅依靠MVCC不能解决幻读问题,必须依赖next-key锁(行锁+gap锁)来解决,这是因为当前读必须获取最新数据。而行锁是把符合条件的数据上锁,放置update,delete操作,间隙所则是把符合条件的附近区间锁住,解决insert插入,即可解决欢度问题。
-
15.4 什么是OLTP和OLAP?
-
15.5 什么是索引?索引有哪些?
-
16 分布式一致性算法
paxos: earlest, hard to understand
zab (zookeeper atomic broadcast): zookeeper
Raft: etcd
Gossip: redis, cassandra -
16.1 分布式事务一致性方案
2PC
算法与模型
-
1 你们用的哪类算法?效果如何?
-
2 数据怎么清洗的?特征工程怎么做的?
-
3 模型怎么训练的?分布式训练知道怎么做吗?
-
3.1 知道分布式训练的原理吗?
-
3.2 分布式训练遇到过什么坑吗?
-
# Recommend System & Recommend Engine
Domain Specific System
-
1 描述一下系统有哪些模块,是怎么组织的?
-
2 如何训练并Serve模型的?
-
3 你提到了KubeFlow私有化部署,你们是怎么使用KubeFlow的?
-
4 如何热更新feature和model?
-
5 如何解决online&offline feature的一致性?
-
6 如何排查数据正确性?
-
7 如何排查精度问题?
-
8 如何排查性能问题?
算法与模型
-
1 特征工程怎么做?
-
2 线下提升线上效果不好为什么,怎么解决?
# Performance Optimization of Inference
框架相关
Device相关
# Self-developed FPGA inference acceleration chip solution
芯片相关
软件相关
# DevOps
-
- 如何做CI的?
-
- 如何做Test的?
-
- 如何做版本发布和回滚的?
-
- 怎么搭私网CI环境?
-
- 如何提升效率与性能?
# 架构设计
# 秒杀系统
作者:阿里云云栖号
链接:https://www.zhihu.com/question/54895548/answer/146924420
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一、为什么难
秒杀系统难做的原因:库存只有一份,所有人会在集中的时间读和写这些数据。
例如小米手机每周二的秒杀,可能手机只有1万部,但瞬时进入的流量可能是几百几千万。
又例如12306抢票,亦与秒杀类似,瞬时流量更甚。二、常见架构
流量到了亿级别,常见站点架构如上:
1)浏览器端,最上层,会执行到一些JS代码
2)站点层,这一层会访问后端数据,拼html页面返回给浏览器
3)服务层,向上游屏蔽底层数据细节
4)数据层,最终的库存是存在这里的,mysql是一个典型三、优化方向
1)将请求尽量拦截在系统上游:传统秒杀系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小【一趟火车其实只有2000张票,200w个人来买,基本没有人能买成功,请求有效率为0】
2)充分利用缓存:这是一个典型的读多写少的应用场景【一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%】,非常适合使用缓存四、优化细节
4.1)浏览器层请求拦截
点击了“查询”按钮之后,系统那个卡呀,进度条涨的慢呀,作为用户,我会不自觉的再去点击“查询”,继续点,继续点,点点点。。。有用么?平白无故的增加了系统负载(一个用户点5次,80%的请求是这么多出来的),怎么整?
a)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求
b)JS层面,限制用户在x秒之内只能提交一次请求
如此限流,80%流量已拦。4.2)站点层请求拦截与页面缓存
浏览器层的请求拦截,只能拦住小白用户(不过这是99%的用户哟),高端的程序员根本不吃这一套,写个for循环,直接调用你后端的http请求,怎么整?
a)同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面
b)同一个item的查询,例如手机车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面
如此限流,又有99%的流量会被拦截在站点层4.3)服务层请求拦截与数据缓存
站点层的请求拦截,只能拦住普通程序员,高级黑客,假设他控制了10w台肉鸡(并且假设买票不需要实名认证),这下uid的限制不行了吧?怎么整?
a)大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?对于写请求,做请求队列,每次只透有限的写请求去数据层,如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”
b)对于读请求,还要我说么?cache抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的
如此限流,只有非常少的写请求,和非常少的读缓存mis的请求会透到数据层去,又有99.9%的请求被拦住了4.4)数据层闲庭信步
到了数据这一层,几乎就没有什么请求了,单机也能扛得住,还是那句话,库存是有限的,小米的产能有限,透这么多请求来数据库没有意义。五、总结
没什么总结了,上文应该描述的非常清楚了,对于秒杀系统,再次重复下笔者的两个架构优化思路:
1)尽量将请求拦截在系统上游
2)读多写少的常用多使用缓存
秒杀系统基本面试被问烂了,网上资料也很多,基本整理了内容如下:
设计难点:并发量大,应用、数据库都承受不了。另外难控制超卖。
设计要点:
将请求尽量拦截在系统上游,html尽量静态化,部署到cdn上面。按钮及时设置为不可用,禁止用户重复提交请求。
设置页面缓存,针对同一个页面和uid一段时间内返回缓存页面。
数据用缓存抗,不直接落到数据库。
读数据的时候不做强一致性教研,写数据的时候再做。
在每台物理机上也缓存商品信息等等变动不大的相关的数据
像商品中的标题和描述这些本身不变的会在秒杀开始之前全量推送到秒杀机器上并一直缓存直到秒杀结束。
像库存这种动态数据会采用被动失效的方式缓存一定时间(一般是数秒),失效后再去Tair缓存拉取最新的数据。
如果允许的话,用异步的模式,等缓存都落库之后再返回结果。
如果允许的话,增加答题教研等验证措施。
其他业务和技术保障措施:
业务隔离。把秒杀做成一种营销活动,卖家要参加秒杀这种营销活动需要单独报名,从技术上来说,卖家报名后对我们来说就是已知热点,当真正开始时我们可以提前做好预热。
系统隔离。系统隔离更多是运行时的隔离,可以通过分组部署的方式和另外 99% 分开。秒杀还申请了单独的域名,目的也是让请求落到不同的集群中。
数据隔离。秒杀所调用的数据大部分都是热数据,比如会启用单独 cache 集群或 MySQL 数据库来放热点数据,目前也是不想0.01%的数据影响另外99.99%。
另外需要复习缓存穿透、雪崩等等问题,主要的流量都落在了缓存数据库上,需要针对缓存数据库的高可用作保障。
# 短链接
这个应该是比较公认的方案了:
分布式ID生成器产生ID
ID转62进制字符串
记录数据库,根据业务要求确定过期时间,可以保留部分永久链接
主要难点在于分布式ID生成。鉴于短链一般没有严格递增的需求,可以使用预先分发一个号段,然后生成的方式。
看了下新浪微博的短链接,8位,理论上可以保存超过200万亿对关系,具体怎么存储的还有待研究。
# 红包
红包系统其实很像秒杀系统,只不过同一个秒杀的总量不大,但是全局的并发量非常大,比如春晚可能几百万人同时抢红包。
主要技术难点也类似,主要在数据库,减库存的时候会抢锁。另外由于业务需求不同,没办法异步,也不能超卖,事务更加严格。
不能采用的方式:
乐观锁:手慢会失败,DB 面临更大压力,所以不能采用。
直接用缓存顶,涉及到钱,一旦缓存挂掉就完了。
建议的方式:
接入层垂直切分,根据红包ID,发红包、抢红包、拆红包、查详情详情等等都在同一台机器上处理,互不影响,分而治之。
请求进行排队,到数据库的时候是串行的,就不涉及抢锁的问题了。
为了防止队列太长过载导致队列被降级,直接打到数据库上,所以数据库前面再加上一个缓存,用CAS自增控制并发,太高的并发直接返回失败。
红包冷热数据分离,按时间分表。
# 分布式ID
分布式ID生成大概也算老生常谈的问题了,主要关键在于是否需要严格递增,严格递增的话效率必然大降。
不需要递增的话比较简单:
一种方式是预先分片,比如十台机器,每台先分一千个ID,一号机从0开始,二号从1000开始等等。缺点是大致上可以被人看出来业务量。
另一种方式是类似雪花算法,每个机器有个id,然后基于时间算一个id,再加上一个递增id。比如如下美团的方案。缺点是机器的时间戳不能回拨,回拨的话会出现问题。
img
如果要求严格递增,我没找到现成的很好的方案,大概只能单机生成,不能分布式了,然后都去单机上取号。效率的话,类似Redis的数据库大概能到每秒十几二十几万的速度。
# 分布式限流
常见的限流方法:
固定窗口计数器:按照时间段划分窗口,有一次请求就+1,最为简单的算法,但这个算法有时会让通过请求量允许为限制的两倍。
滑动窗口计数器:通过将窗口再细分,并且按照时间“滑动”来解决突破限制的问题,但是时间区间的精度越高,算法所需的空间容量就越大。
漏桶:请求类似水滴,先放到桶里,服务的提供方则按照固定的速率从桶里面取出请求并执行。缺陷也很明显,当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。
令牌桶:往桶里面发放令牌,每个请求过来之后拿走一个令牌,然后只处理有令牌的请求。令牌桶满了则多余的令牌会直接丢弃。令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
Google 的开源项目 guava 提供了 RateLimiter 类,实现了单点的令牌桶限流。
分布式环境下,可以考虑用 Redis+Lua 脚本实现令牌桶。
如果请求量太大了,Redis 也撑不住怎么办?我觉得可以类似于分布式 ID 的处理方式,Redis 前面在增加预处理,比如每台及其预先申请一部分令牌,只有令牌用完之后才去 Redis。如果还是太大,是否可以垂直切分?按照流量的来源,比如地理位置、IP 之类的再拆开。
# 分布式定时任务
任务轮询或任务轮询+抢占排队方案
每个服务器首次启动时加入队列;
每次任务运行首先判断自己是否是当前可运行任务,如果是便运行;
如果不是当前运行的任务,检查自己是否在队列中,如果在,便退出,如果不在队列中,进入队列。
# 微博推送
主要难点:关系复杂,数据量大。一个人可以关注非常多的用户,一个大 V 也有可能有几千万的粉丝。
先介绍最基本的方案:
推模式:推模式就是,用户A关注了用户 B,用户 B 每发送一个动态,后台遍历用户B的粉丝,往他们粉丝的 feed 里面推送一条动态。
拉模式:推模式相反,拉模式则是,用户每次刷新 feed 第一页,都去遍历关注的人,把最新的动态拉取回来。
一般采用推拉结合的方式,用户发送状态之后,先推送给粉丝里面在线的用户,然后不在线的那部分等到上线的时候再来拉取。
另外冷热数据分离,用户关系在缓存里面可以设置一个过期时间,比如七天。七天没上线的可能就很少用这个 APP。
# 大文件排序
对于远高于内存的文件排序。
外归并排序:
- 对文件分割,然后分别排序
- 排好序的文件依次读取一个缓冲区的大小,然后进行排序,输出到输出缓冲区,然后保存到结果文件。
如果是数字,可以用位图排序,但是要求比较苛刻:
数字不重复
知道最大值
相对密集,因为没出现的数字也会占用空间
比较适合电话号之类的。
# IM ID
IM消息ID技术专题(一):微信的海量IM聊天消息序列号生成实践(算法原理篇
# top K
在大规模数据处理中,经常会遇到的一类问题:在海量数据中找出出现频率最好的前k个数,或者从海量数据中找出最大的前k个数,这类问题通常被称为top K问题。例如,在搜索引擎中,统计搜索最热门的10个查询词;在歌曲库中统计下载最高的前10首歌等。
针对top K类问题,通常比较好的方案是分治+Trie树/hash+小顶堆(就是上面提到的最小堆),即先将数据集按照Hash方法分解成多个小数据集,然后使用Trie树活着Hash统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出现频率最高的前K个数,最后在所有top K中求出最终的top K。
(1)有10000000个记录,这些查询串的重复度比较高,如果除去重复后,不超过3000000个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。请统计最热门的10个查询串,要求使用的内存不能超过1GB。
(2)有10个文件,每个文件1GB,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。按照query的频度排序。
(3)有一个1GB大小的文件,里面的每一行是一个词,词的大小不超过16个字节,内存限制大小是1MB。返回频数最高的100个词。
(4)提取某日访问网站次数最多的那个IP。
(5)10亿个整数找出重复次数最多的100个整数。
(6)搜索的输入信息是一个字符串,统计300万条输入信息中最热门的前10条,每次输入的一个字符串为不超过255B,内存使用只有1GB。
(7)有1000万个身份证号以及他们对应的数据,身份证号可能重复,找出出现次数最多的身份证号。
在海量数据中查找出重复出现的元素或者去除重复出现的元素也是常考的问题。针对此类问题,一般可以通过位图法实现。例如,已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
本题最好的解决方法是通过使用位图法来实现。8位整数可以表示的最大十进制数值为99999999。如果每个数字对应于位图中一个bit位,那么存储8位整数大约需要99MB。因为1B=8bit,所以99Mbit折合成内存为99/8=12.375MB的内存,即可以只用12.375MB的内存表示所有的8位数电话号码的内容。
# 高并发
-
1 高并发缓存、限流、降级
Sentinel-Go 现代微服务架构基本都是分布式的,整个分布式系统由非常多的微服务组成。不同服务之间相互调用,组成复杂的调用链路。前面描述的问题在分布式链路调用中会产生放大的效果。整个复杂链路中的某一环如果不稳定,就可能会层层级联,最终可能导致整个链路全部挂掉。因此我们需要对不稳定的 弱依赖服务调用 进行 熔断降级,暂时切断不稳定的服务调用,避免局部不稳定因素导致整个分布式系统的雪崩。熔断降级作为保护服务自身的手段,通常在客户端(调用端)进行配置。
# 亮点,足够深入,足够了解
性能优化、工程化、缓存、http
Shopee面经
1 | |