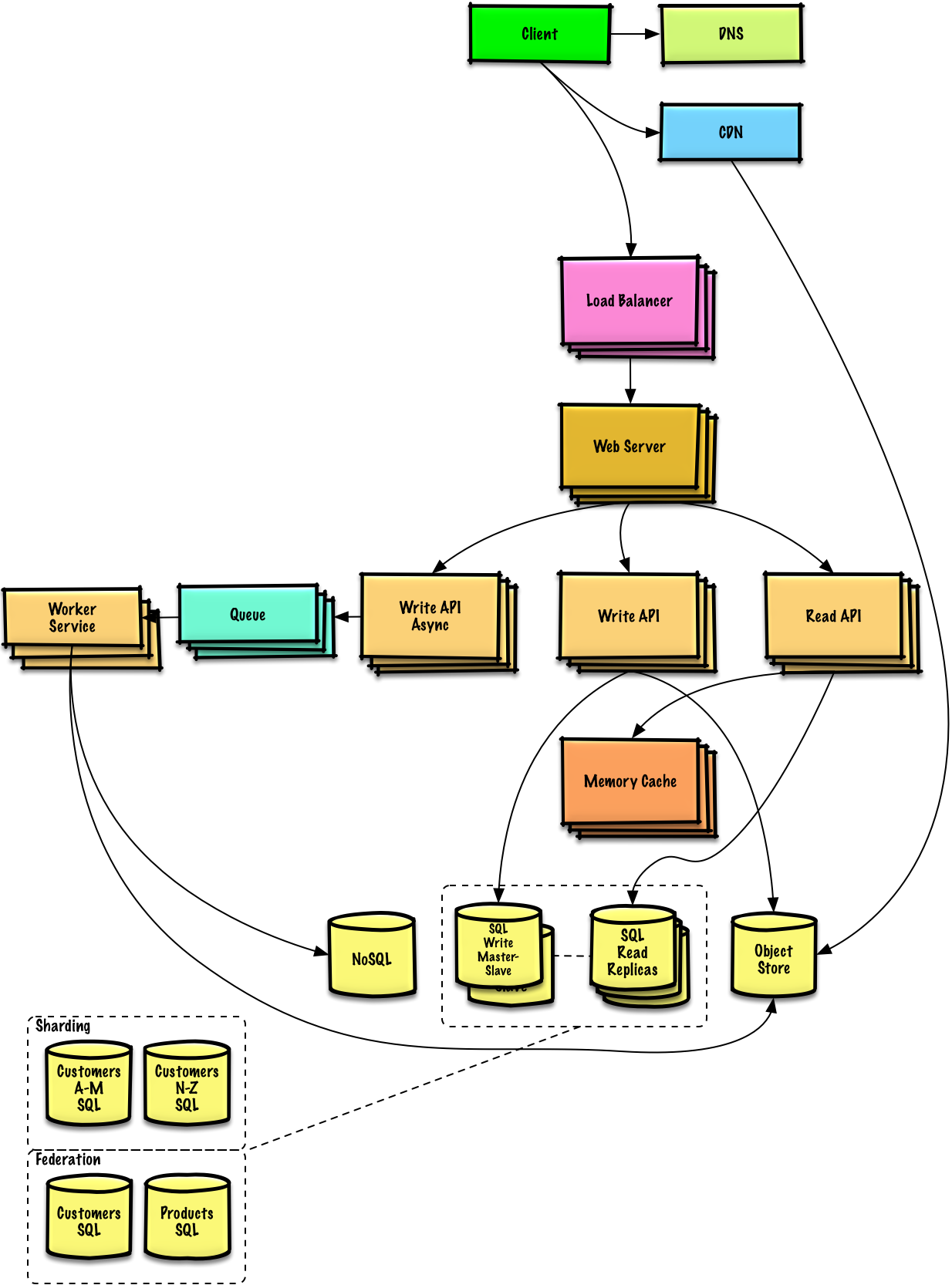
# Database
# CAP
# Table
# Primary Key
uuid vs snowflake [3]
# SQL
# MySQL
# SQL Injection
# NoSQL
# Salt
SHA256 bcrypt
[6]
bcrypt()
# Vertical partitioning and Horizontal partitioning
Sharding Horizontal Partitioning
# Access Times
# OLTP vs OLAP
OLTP and OLAP: The two terms look similar but refer to different kinds of systems. Online transaction processing (OLTP) captures, stores, and processes data from transactions in real time. Online analytical processing (OLAP) uses complex queries to analyze aggregated historical data from OLTP systems.
# Key
🔹 Globally unique - If IDs are not globally unique, there could be collisions.
🔹 Roughly sorted by time - So user IDs, post IDs can be sorted by time without fetching additional info.
🔹 Numerical values only - Naturally sortable by time.
🔹 64 bits - 2^32 = ~4 billion -> not enough IDs | 2^64 is big enough | 2^128 waste space
🔹 Highly scalable, low latency | Ability to generate a lot of IDs per second in low latency fashion is critical.
- DB auto-increment: easy but only for single server setup
- UUID Easy to generate globally unique, not sorted by time, not numeric
- Snowflake open sourced by Twitter, widely used in the industry, discord/twitter uses this
# Cache
# Hot Data
# Elimination Strategy
# LRU
# LFU
# Monitor
# Real Time Stream Processing
# Availability
# Fuse
# Traffic Control
# Replica Set
# Network
# Protocol
# HTTP
HTTP 1.0
HTTP over TCP
HTTP 1.1
Persistent connection “keep-alive”
HOL (head-of-line) blocking issue in HTTP layer
HTTP 2.0 2015
HTTP streams
HOL in transport layer
HTTP 3.0
HTTP over QUIC
QUIC on UDP
# QUIC
- 连接迁移 use unique id rather than ip-port tuples.
- low-latency handshake 0-RTT
- customizable congestion control
- No HOL blocking
# HTTPS
TLS
- client -> hello -> server
- server -> certificate -> client
- client -> verify certificate -> Certificate Server
- client -> session key | public key encrypted RSA -> server
- server -> private key decrypt RSA | session key
- server -> AES symmetric encrypt with session key | content -> client
- client -> decrypt with session key | content
how much performance overhead does HTTPS add, compared to HTTP?
Assume a common MTU of 1500 bytes packet size ; the HTTPS protocol overhead will still leave at least 1400 bytes effective payload data size, therefore in max 6-7% increase in bandwidth.
The pure data-transfer speed penalty is negligible.
# TCP
# RPC
# RESTful
# Authentication
#
# Session
# Token
expired time
replay attack
rely on server-side key, only for single server
# HMAC(AK/SK)
Hash-based message authentication code
compute on every request
no expired time, delete on server anytime
generate multiple
# CSRF
跨站伪造请求
- 阻止不明外域的访问
- 同源检测
- Samesite Cookie
- 提交时要求附加本域才能获取的信息
- CSRF Token
- 双重Cookie验证
# XSS
跨站脚本攻击
Content Security Policy
- 禁止加载外域代码,防止复杂的攻击逻辑。
- 禁止外域提交,网站被攻击后,用户的数据不会泄露到外域。
- 禁止内联脚本执行(规则较严格,目前发现 GitHub 使用)。
- 禁止未授权的脚本执行(新特性,Google Map 移动版在使用)。
- 合理使用上报可以及时发现 XSS,利于尽快修复问题。
输入内容长度控制
对于不受信任的输入,都应该限定一个合理的长度。虽然无法完全防止 XSS 发生,但可以增加 XSS 攻击的难度。
其他安全措施
- HTTP-only Cookie: 禁止 JavaScript 读取某些敏感 Cookie,攻击者完成 XSS 注入后也无法窃取此 Cookie。
- 验证码:防止脚本冒充用户提交危险操作。
# Replay Attack
a hacker intercepts your data and resends the same web request to a server, so it looks like that data is coming from your browser.
- Adding timestamps on all messages. You can create a timestamp on your server and set it to ignore any requests that are older than your selected time frame. This means that a server can detect which messages fail to meet your timestamp requirements, and then ignore them.
- Using SSL or TLS. When a website supports SSL or TLS security protocols, all the data traveling between a browser and a server is encrypted. Hackers won’t be able to spy on your session ID and use it to impersonate you.
- Using one-time passwords. This method is mostly used by banks to authenticate their users and prevent criminals from accessing their clients’ accounts.
# Cache Miss Attack
-
Cache Non-existent keys, Set a short TTL (Time to Live) for keys with null value.
-
Use bloom filters Key exists | Key not exists
# CDN
# Encryption
# RSA
# AES
非对称加密相比对称加密的显著优点在于,对称加密需要协商密钥,而非对称加密可以安全地公开各自的公钥,在N个人之间通信的时候:使用非对称加密只需要N个密钥对,每个人只管理自己的密钥对。而使用对称加密需要则需要N*(N-1)/2个密钥,因此每个人需要管理N-1个密钥,密钥管理难度大,而且非常容易泄漏。
既然非对称加密这么好,那我们抛弃对称加密,完全使用非对称加密行不行?也不行。因为非对称加密的缺点就是运算速度非常慢,比对称加密要慢很多。
所以,在实际应用的时候,非对称加密总是和对称加密一起使用。假设小明需要给小红需要传输加密文件,他俩首先交换了各自的公钥,然后:
小明生成一个随机的AES口令,然后用小红的公钥通过RSA加密这个口令,并发给小红;
小红用自己的RSA私钥解密得到AES口令;
双方使用这个共享的AES口令用AES加密通信。
可见非对称加密实际上应用在第一步,即加密“AES口令”。这也是我们在浏览器中常用的HTTPS协议的做法,即浏览器和服务器先通过RSA交换AES口令,接下来双方通信实际上采用的是速度较快的AES对称加密,而不是缓慢的RSA非对称加密。
# Safety
# Password
如何存储密码?
- 不要直接存储明文,存储哈希值
- 加盐,防止查表破解
- 使用慢速hash函数让破解更加困难,比如PBKDF2或者bcrypt, Blowfish-based crypt
# OS
# Process vs Thread
# Debug
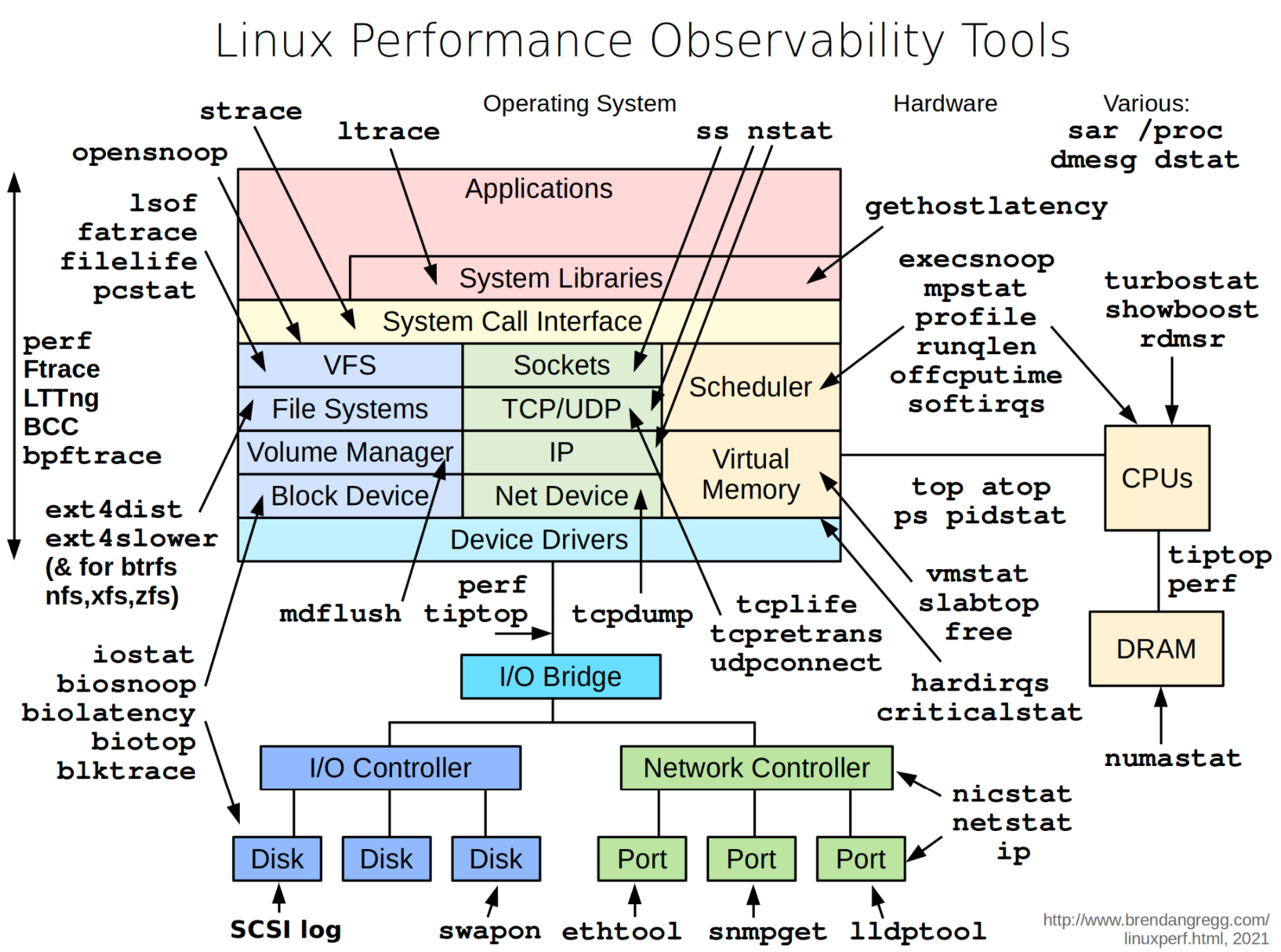
# Microservices
There are two ways: orchestration and choreography
# Virtualization
Virtualization is a technology that allows you to create multiple
simulated environments or dedicated resources from a single, physical
hardware system
Containerization is the packaging together of software code with all its
necessary components like libraries, frameworks, and other
dependencies so that they are isolated in their own “container”
# Bloom Filter
Multiple hash functions get multiple hashing results converted to a one-hot vector.
For the element we want to test, get hashing results from the same hash functions. If all bits are occupied, it may exist.
At least one bit is marked with 0, it definitely not exists.
假设元素的全集个数为 n, 过滤器槽为 m, 共有 k 个函数, 那么误判率为 (1-e(-kn/m))k
Your false positive rate will be approximately (1-e-kn/m)k, so you can just plug the number n of elements you expect to insert, and try various values of k and m to configure your filter for your application.
The more hash functions you have, the slower your bloom filter, and the quicker it fills up. If you have too few, however, you may suffer too many false positives.
Since you have to pick k when you create the filter, you’ll have to ballpark what range you expect n to be in. Once you have that, you still have to choose a potential m (the number of bits) and k (the number of hash functions).
So, to choose the size of a bloom filter, we:
- Choose a ballpark value for n
- Choose a value for m
- Calculate the optimal value of k
- Calculate the error rate for our chosen values of n, m, and k. If it’s unacceptable, return to step 2 and change m; otherwise we’re done.
# Case
# Strategies
read
- Cache Aside read caches first if data exists or read database and write cache
- Read Through read cache, cache read db
write
- Write Around Write to db, then read from cache = write to db + cache aside
- Write Back applications write to caches constantly, caches write to dbs once in a while
- Write Through applications write to caches constantly, caches write to db immediately
# Global
# Multi-site high availability (HA) and disaster recovery (DR)
feature allows customers to deploy field-proven high availability and disaster recovery solutions over multiple sites, keeping three concurrent copies of data.
# Globally Distributed Application
# CDN
- IP whitelist
- Referer
- Timestamp
- Centralized Authentication
# Block storage, file storage and object storage
# Design Recommend System
# Design Short Link Service
# Design Shopee
# Design TikTok
# Design Dropbox
# Design Netflix
# Design E-commerce spike activity
# Design Video Transcoding System
# Design Task Queue
# Story
# Handling a large-scale outage
This is a true story about handling a large-scale outage written by Staff
Engineers at Discord Sahn Lam.
About 10 years ago, I witnessed the most impactful UI bugs in my
career.
It was 9PM on a Friday. I was on the team responsible for one of the
largest social games at the time. It had about 30 million DAU. I just so
happened to glance at the operational dashboard before shutting down
for the night.
Every line on the dashboard was at zero.
At that very moment, I got a phone call from my boss. He said the
entire game was down. Firefighting mode. Full on.
Everything had shut down. Every single instance on AWS was
terminated. HA proxy instances, PHP web servers, MySQL databases,
Memcache nodes, everything.
It took 50 people 10 hours to bring everything back up. It was quite a
feat. That in itself is a story for another day.
We used a cloud management software vendor to manage our AWS
deployment. This was before Infrastructure as Code was a thing. There
was no Terraform. It was so early in cloud computing and we were so
big that AWS required an advanced warning before we scaled up.
What had gone wrong? The software vendor had introduced a bug that
week in their confirmation dialog flow. When terminating a subset of
nodes in the UI, it would correctly show in the confirmation dialog box
the list of nodes to be terminated, but under the hood, it terminated
everything.
Shortly before 9PM that fateful evening, one of our poor SREs fulfilled
our routine request and terminated an unused Memcache pool. I could
only imagine the horror and the phone conversation that ensured.
49
What kind of code structure could allow this disastrous bug to slip
through? We could only guess. We never received a full explanation.
What are some of the most impactful software bugs you encountered
in your career?