- Basics
- What is Kubernetes?
- How Container orchestration is beneficial?
- How are Kubernetes and Docker related?
- What is a node in Kubernetes?
- What are pods in Kubernetes?
- What is a Kubernetes deployment?
- Explain the use case of Kubernetes deployment?
- What is the difference between a pod and a deployment?
- What are Kubernetes Services?
- What is replicaset in kubernetes?
- What are clusters in Kubernetes?
- What are Daemon sets?
- What is Heapster in Kubernetes?
- What is a Namespace in Kubernetes?
- Why use namespaces?
- What is the Kubernetes controller manager?
- What are the types of controller managers?
- What’s the components in Kubernetes’s control plane?
- What’s the core components in a Kubernetes Node?
- What is ETCD in Kubernetes?
- What is ClusterIP?
- What is NodePort?
- [What is a headless service[3]?](#what-is-a-headless-service-3)
- What is Kubelet?
- What is the Load Balancer in Kubernetes?
- What is Kubectl?
- What is Kube-proxy?
- Can we put multiple containers inside a pod?
- Name some container patterns you come across or use?
- What is Init Container Pattern?
- When do you use Init Container Pattern?
- How do you configure resource limits for the Init Container Pattern?
- What is Sidecar Container Design?
- When do you use Sidecar Container Pattern?
- How do you configure resource limits for the Sidecar Container Pattern?
- What is Adapter Container Pattern?
- When do you use Adapter Container Pattern?
- How do you configure resource limits for the Adapter Container Pattern?
- What is Ambassador Container Pattern?
- When do you use Ambassador Container Pattern?
- How do you configure resource limits for the Ambassador Container Pattern?
- Point out the tools which are utilized for container monitoring?
- Disadvantages of Kubernetes
- Why use Kubernetes?
- What is the function of clusters in Kubernetes?
- Characteristics of Kubernetes?
- Define Ingress network
- List the uses of GKE
- Explain the main components of Kubernetes architecture?
- How do we control the resource usage of POD?
- What are the various K8s services running on nodes and describe the role of each service?
- What is PDB (Pod Disruption Budget)?
- What are the various things that can be done to increase Kubernetes security?
- How to monitor the Kubernetes cluster?
- How to get the central logs from POD?
- How to turn the service defined below in the spec into an external one?
- How to configure TLS with Ingress?
- What is a Kubernetes Operator?
- Why do we need Operators?
- What difference do you find between Docker Swarm and Kubernetes?
- What difference do you find between deploying applications on the host and containers?
- What is Minikube?
- How Kubernetes simplifies the containerized Deployment
- What is the role of Kube-apiserver and Kube-scheduler?
- How do master nodes in Kubernetes work?
- What are the different types of services in Kubernetes?
- What do you understand about Cloud controller managers?
- What is the difference between a replica set and a replication controller?
- What are federated clusters?
- hat are the best security measures that you can take while using Kubernetes?
- What are the main differences between the Docker Swarm and Kubernetes?
- What are the types of secrets available in Kubernetes?
- How to use secrets in Kubernetes?
- How to Create and Use ConfigMap with Kubernetes?
- What is a Kubernetes StatefulSet?
- What are levels of abstraction in Kubernetes?
- How to Configure Kubernetes for Rolling Update?
- What is the difference between Docker Compose and Kubernetes?
- What is the difference between kubernetes load balancer and ingress controller?
- When would you use a Deployment versus a StatefulSet versus a DaemonSet?
- What are container orchestrators and why are they required?
- What type of workloads run well on Kubernetes, and what types do not?
- What is the Operator pattern and when should you use it?
- How can RBAC be used to grant permission to Kubernetes resources?
- What is Helm Charts?
- How to persist data in kubernetes using volumes?
- How to create storage class in kubernetes?
# Basics
# What is Kubernetes?
Kubernetes is an open-source container orchestration tool or system that is used to automate tasks such as the management, monitoring, scaling, and deployment of containerized applications. It is used to easily manage several containers (since it can handle grouping of containers), which provides for logical units that can be discovered and managed.
# How Container orchestration is beneficial?
Container orchestration is a process of managing the life cycles of containers more specifically in large & dynamic environments. All the services in the individual container are in synchronization to fulfill the needs of the server. Container orchestration is used to regulate and automate tasks such as:
- Provisioning and deployment of containers
- Upscaling or removing containers to divide application load evenly all across host infrastructure
- Redundancy and availability of containers
- Moving of containers from one host to another in case there is a shortage of resources in a host (or when the host dies)
- Allocation resources across containers
- Health monitoring of containers and hosts
- Externally exposing services running in a container to the outside world
- Load balancing of service discovery across containers
- Configuring an application relative to the containers running it
#
Docker is an open-source platform used to handle software development. Its main benefit is that it packages the settings and dependencies that the software/application needs to run into a container, which allows for portability and several other advantages. Kubernetes allows for the manual linking and orchestration of several containers, running on multiple hosts that have been created using Docker.
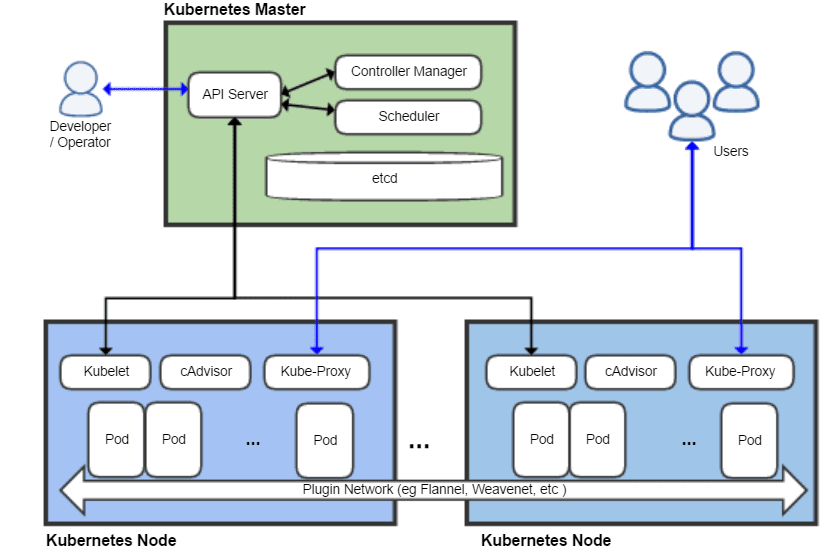
# What is a node in Kubernetes?
A node is the smallest fundamental unit of computing hardware. It represents a single machine in a cluster, which could be a physical machine in a data center or a virtual machine from a cloud provider. Each machine can substitute any other machine in a Kubernetes cluster. The master in Kubernetes controls the nodes that have containers.
# What are pods in Kubernetes?
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes.
A Pod is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. Containers in the same pod share a local network and the same resources, allowing them to easily communicate with other containers in the same pod as if they were on the same machine while at the same time maintaining a degree of isolation.
# What is a Kubernetes deployment?
A Kubernetes deployment is a resource object in Kubernetes that provides declarative updates to applications. A deployment allows you to describe an application’s life cycle, such as which images to use for the app, the number of pods there should be, and the way in which they should be updated.
# Explain the use case of Kubernetes deployment?
The following are typical use cases for Deployments:
- Create a Deployment to rollout a ReplicaSet. The ReplicaSet creates Pods in the background. Check the status of the rollout to see if it succeeds or not.
- Declare the new state of the Pods by updating the PodTemplateSpec of the Deployment. A new ReplicaSet is created and the Deployment manages moving the Pods from the old ReplicaSet to the new one at a controlled rate. Each new ReplicaSet updates the revision of the Deployment.
- Rollback to an earlier Deployment revision if the current state of the Deployment is not stable. Each rollback updates the revision of the Deployment.
- Scale up the Deployment to facilitate more load.
- Pause the Deployment to apply multiple fixes to its PodTemplateSpec and then resume it to start a new rollout.
- Use the status of the Deployment as an indicator that a rollout has stuck.
- Clean up older ReplicaSets that you don’t need anymore
# What is the difference between a pod and a deployment?
A pod is the core building block for running applications in a Kubernetes cluster; a deployment is a management tool used to control the way pods behave.
Both Pod and Deployment are full-fledged objects in the Kubernetes API. Deployment manages creating Pods by means of ReplicaSets. What it boils down to is that Deployment will create Pods with spec taken from the template. It is rather unlikely that you will ever need to create Pods directly for a production use-case.
# What are Kubernetes Services?
A Kubernetes Service is an abstraction which defines a logical set of Pods running somewhere in your cluster, that all provide the same functionality. When created, each Service is assigned a unique IP address (also called clusterIP). This address is tied to the lifespan of the Service, and will not change while the Service is alive.
Pods can be configured to talk to the Service, and know that communication to the Service will be automatically load-balanced out to some pod that is a member of the Service.
# What is replicaset in kubernetes?
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods.
# What are clusters in Kubernetes?
A Kubernetes cluster is a set of nodes used for running containerized applications, so when you are running Kubernetes, you are running a cluster. A cluster contains a control plane & one or maybe more than one compute machines/nodes.
- The control plane is used to maintain the desired state of the cluster, such as which applications are running or which container images they use.
- Whereas, the nodes run the applications and the workloads.
Clusters are the heart of Kubernetes that gives the ability to schedule and run the containers across a group of machines - physical, virtual, on-premise, or in the cloud. Kubernetes containers aren’t tied to any particular machines, they are abstracted across the cluster.
# What are Daemon sets?
A Daemon set is a set of pods that runs only once on a host. They are used for host layer attributes like a network or for monitoring a network, which you may not need to run on a host more than once.
# What is Heapster in Kubernetes?
A Heapster is a performance monitoring and metrics collection system for data collected by the Kublet. This aggregator is natively supported and runs like any other pod within a Kubernetes cluster, which allows it to discover and query usage data from all nodes within the cluster.
# What is a Namespace in Kubernetes?
Namespaces are used for dividing cluster resources between multiple users. They are meant for environments where there are many users spread across projects or teams and provide a scope of resources.
# Why use namespaces?
While using the default namespace alone, it becomes hard over time to get an overview of all the applications you can manage in your cluster. Namespaces make it easier to organize the applications into groups that make sense, like a namespace of all the monitoring applications and a namespace for all the security applications, etc.
Namespaces can also be useful for managing Blue/Green environments where each namespace can include a different version of an app and also share resources that are in other namespaces (namespaces like logging, monitoring, etc.).
Another use case for namespaces is one cluster with multiple teams. When multiple teams use the same cluster, they might end up stepping on each other’s toes. For example, if they end up creating an app with the same name it means one of the teams overrides the app of the other team because there can’t be two apps in Kubernetes with the same name (in the same namespace).
# What is the Kubernetes controller manager?
In Kubernetes, different methods are operating on the master node, and they are accumulated together as the Kubernetes Controller Manager. It is a daemon which installs regulators, including the given below:
- Replication Controller: Maintains pods for each replication object
- Node Controller: Manages the status, mainly, making, refreshing and erasing nodes
- Endpoint controller: Maintain the endpoint objects (pods and administrations)
- Administration record and token regulator: Concerned with the default records and API access tokens for new namespaces
# What are the types of controller managers?
The primary controller managers that can run on the master node are the endpoints controller, service accounts controller, namespace controller, node controller, token controller, and replication controller.
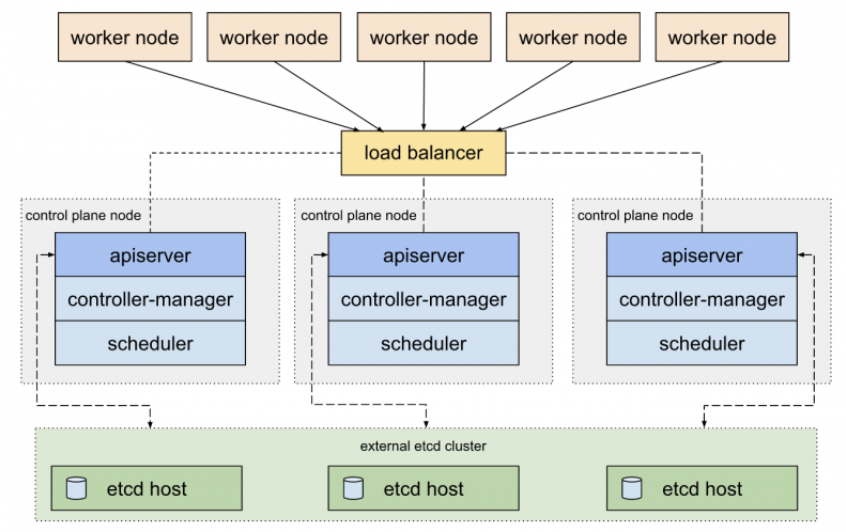
# What’s the components in Kubernetes’s control plane?

The control plane includes [4][5]:
- kube-apiserver. Provides an API that serves as the front end of a Kubernetes control plane. It is responsible for handling external and internal requests—determining whether a request is valid and then processing it. The API can be accessed via the kubectl command-line interface or other tools like kubeadm, and via REST calls.
- kube-scheduler. This component is responsible for scheduling pods on specific nodes according to automated workflows and user defined conditions, which can include resource requests, concerns like affinity and taints or tolerations, priority, persistent volumes (PV), and more
- kube-controller-manager. The Kubernetes controller manager is a control loop that monitors and regulates the state of a Kubernetes cluster. It receives information about the current state of the cluster and objects within it, and sends instructions to move the cluster towards the cluster operator’s desired state.
The controller manager is responsible for several controllers that handle various automated activities at the cluster or pod level, including replication controller, namespace controller, service accounts controller, deployment, statefulset, and daemonset. - etcd. A key-value database that contains data about your cluster state and configuration. Etcd is fault tolerant and distributed.
- cloud-controller-manager. This component can embed cloud-specific control logic - for example, it can access the cloud provider’s load balancer service. It enables you to connect a Kubernetes cluster with the API of a cloud provider. Additionally, it helps decouple the Kubernetes cluster from components that interact with a cloud platform, so that elements inside the cluster do not need to be aware of the implementation specifics of each cloud provider.
This cloud-controller-manager runs only controllers specific to the cloud provider. It is not required for on-premises Kubernetes environments. It uses multiple, yet logically-independent, control loops that are combined into one binary, which can run as a single process. It can be used to add scale a cluster by adding more nodes on cloud VMs, and leverage cloud provider high availability and load balancing capabilities to improve resilience and performance.
# What’s the core components in a Kubernetes Node?
The core components includes [4:1]:
- Nodes. Nodes are physical or virtual machines that can run pods as part of a Kubernetes cluster. A cluster can scale up to 5000 nodes. To scale a cluster’s capacity, you can add more nodes.
- Pods. A pod serves as a single application instance, and is considered the smallest unit in the object model of Kubernetes. Each pod consists of one or more tightly coupled containers, and configurations that govern how containers should run. To run stateful applications, you can connect pods to persistent storage, using Kubernetes Persistent Volumes.
- Container Runtime Engine. Each node comes with a container runtime engine, which is responsible for running containers. Docker is a popular container runtime engine, but Kubernetes supports other runtimes that are compliant with Open Container Initiative, including CRI-O and rkt.
- kubelet. Each node contains a kubelet, which is a small application that can communicate with the Kubernetes control plane. The kubelet is responsible for ensuring that containers specified in pod configuration are running on a specific node, and manages their lifecycle… It executes the actions commanded by your control plane.
- kube-proxy. All compute nodes contain kube-proxy, a network proxy that facilitates Kubernetes networking services. It handles all network communications outside and inside the cluster, forwarding traffic or replying on the packet filtering layer of the operating system.
- Container Networking. Container networking enables containers to communicate with hosts or other containers. It is often achieved by using the container networking interface (CNI), which is a joint initiative by Kubernetes, Apache Mesos, Cloud Foundry, Red Hat OpenShift, and others.
CNI offers a standardized, minimal specification for network connectivity in containers. You can use the CNI plugin by passing the kubelet --network-plugin=cni command-line option. The kubelet can then read files from --cni-conf-dir and use the CNI configuration when setting up networking for each pod.
# What is ETCD in Kubernetes?
Kubernetes uses etcd as a distributed key-value store for all of its data, including metadata and configuration data, and allows nodes in Kubernetes clusters to read and write data. Although etcd was purposely built for CoreOS, it also works on a variety of operating systems (e.g., Linux, BSB, and OS X) because it is open-source. Etcd represents the state of a cluster at a specific moment in time and is a canonical hub for state management and cluster coordination of a Kubernetes cluster.
# What is ClusterIP?
The ClusterIP is the default Kubernetes service that provides a service inside a cluster (with no external access) that other apps inside your cluster can access.
# What is NodePort?
The NodePort service is the most fundamental way to get external traffic directly to your service. It opens a specific port on all Nodes and forwards any traffic sent to this port to the service.
# What is a headless service[3:1]?
A headless service is used to interface with service discovery mechanisms without being tied to a ClusterIP, therefore allowing you to directly reach pods without having to access them through a proxy. It is useful when neither load balancing nor a single Service IP is required.
# What is Kubelet?
The kubelet is a service agent that controls and maintains a set of pods by watching for pod specs through the Kubernetes API server. It preserves the pod lifecycle by ensuring that a given set of containers are all running as they should. The kubelet runs on each node and enables the communication between the master and slave nodes.
# What is the Load Balancer in Kubernetes?
A load balancer gives a standard method to convey network traffic among various backend administrations, subsequently boosting adaptability. Contingent upon the workplace, there can be two kinds of load balancer, Internal or External. The Internal Load Balancer can naturally adjust the load and distribute the necessary configuration to the pods. Then again, the External Load Balancer directs the outside load traffic to the backend pods. In Kubernetes, the two load adjusting techniques work through the kube-proxy highlight.
# What is Kubectl?
Kubectl is a CLI (command-line interface) that is used to run commands against Kubernetes clusters. As such, it controls the Kubernetes cluster manager through different create and manage commands on the Kubernetes component.
# What is Kube-proxy?
Kube-proxy is an implementation of a load balancer and network proxy used to support service abstraction with other networking operations. Kube-proxy is responsible for directing traffic to the right container based on IP and the port number of incoming requests.
# Can we put multiple containers inside a pod?
Yes. A pod that contains one container refers to a single container pod and it is the most common kubernetes use case. A pod that contains Multiple co-related containers refers to a multi-container pod.
# Name some container patterns you come across or use?
- Init Container Pattern
- Sidecar Container Pattern
- Adapter Container Pattern
- Ambassador Container Pattern
# What is Init Container Pattern?
Init Containers are the containers that should run and complete before the startup of the main container in the pod. It provides a separate lifecycle for the initialization so that it enables separation of concerns in the applications.
All the init Containers will be executed sequentially and if there is an error in the Init container the pod will be restarted which means all the Init containers are executed again. So, it’s better to design your Init container as simple, quick, and Idompodent.
Example:
1 | |
# When do you use Init Container Pattern?
You can use this pattern where your application or main containers need some prerequisites such as installing some software, database setup, permissions on the file system before starting.
You can use this pattern where you want to delay the start of the main containers.
# How do you configure resource limits for the Init Container Pattern?
Configuring resource limits is very important when it comes to Init containers. The main point we need to understand here is Init containers run first before the start of the main container so when you configure resource limits for the pod you have to take that into consideration.
- The highest init container resource limits (since Init containers run sequentially)
- The sum of all the resource limits of the main containers (Since all the application containers run in parallel)
# What is Sidecar Container Design?
Sidecar containers are the containers that should run along with the main container in the pod. This sidecar pattern extends and enhances the functionality of current containers without changing it.
Imagine that you have the pod with a single container working very well and you want to add some functionality to the current container without touching or changing, how can you add the additional functionality or extending the current functionality? This sidecar container pattern really helps exactly in that situation.
All the Containers will be executed parallelly and the whole functionality works only if both types of containers are running successfully. Most of the time these sidecar containers are simple and small that consume fewer resources than the main container.
Example:
1 | |
# When do you use Sidecar Container Pattern?
- Whenever you want to extend the functionality of the existing single container pod without touching the existing one.
- Whenever you want to enhance the functionality of the existing single container pod without touching the existing one.
- You can use this pattern to synchronize the main container code with the git server pull.
- You can use this pattern for sending log events to the external server.
- You can use this pattern for network-related tasks.
# How do you configure resource limits for the Sidecar Container Pattern?
Configuring resource limits is very important when it comes to Sidecar containers. The main point we need to understand here is All the containers run in parallel so when you configure resource limits for the pod you have to take that into consideration.
- The sum of all the resource limits of the main containers as well as sidecar containers (Since all the containers run in parallel)
# What is Adapter Container Pattern?
There are so many applications that are heterogeneous in nature which means they don’t contain the same interface or not consistent with other systems. This pattern extends and enhances the functionality of current containers without changing it as the sidecar container pattern.
Imagine that you have the pod with a single container working very well but, it doesn’t have the same interface with other systems to integrate or work with it. How can you make this container to have a unified interface with a standardized format so that other systems can to your container? This adapter container pattern really helps exactly in that situation.
All the Containers will be executed parallelly and the whole functionality works only if both types of containers are running successfully. Most of the time these adapter containers are simple and small that consume fewer resources than the main container.
Example:
1 | |
# When do you use Adapter Container Pattern?
- Whenever you want to extend the functionality of the existing single container pod without touching the existing one.
- Whenever you want to enhance the functionality of the existing single container pod without touching the existing one.
- Whenever there is a need to convert or standardize the format for the rest of the systems.
# How do you configure resource limits for the Adapter Container Pattern?
Configuring resource limits is very important when it comes to Adapter containers. The main point we need to understand here is All the containers run in parallel so when you configure resource limits for the pod you have to take that into consideration.
- The sum of all the resource limits of the main containers as well as adapter containers (Since all the containers run in parallel)
# What is Ambassador Container Pattern?
The Ambassador container is a special type of sidecar container which simplifies accessing services outside the Pod. When you are running applications on kubernetes it’s a high chance that you should access the data from the external services. The Ambassador container hides the complexity and provides the uniform interface to access these external services.
Imagine that you have the pod with one container running successfully but, you need to access external services. But, these external services are dynamic in nature or difficult to access. Sometimes there is a different format that external service returns. There are some other reasons as well and you don’t want to handle this complexity in the main container. So, we use the Ambassador containers to handle these kinds of scenarios.
All the Containers will be executed parallelly and the whole functionality works only if both types of containers are running successfully. Most of the time these ambassador containers are simple and small that consume fewer resources than the main container.
Example:
1 | |
# When do you use Ambassador Container Pattern?
- Whenever you want to hide the complexity from the main container such as service discovery.
- Whenever your containerized services want to talk to external services you can use this pattern to handle the request and response for these services.
- Whenever there is a need to convert or standardize the format of external services responses.
# How do you configure resource limits for the Ambassador Container Pattern?
Configuring resource limits is very important when it comes to Ambassador containers. The main point we need to understand here is All the containers run in parallel so when you configure resource limits for the pod you have to take that into consideration.
- The sum of all the resource limits of the main containers as well as ambassador containers (Since all the containers run in parallel)
# Point out the tools which are utilized for container monitoring?
Tools which are utilized for container monitoring are:
# Disadvantages of Kubernetes
- Kubernetes dashboard isn’t as useful as it ought to be
- Security isn’t viable.
- It is intricate and can diminish profitability
- Kubernetes is more costlier than its other options.
# Why use Kubernetes?
Kubernetes is utilized on the grounds that:
- It causes you to evade vendor lock issues as it can utilize any vendor explicit APIs or administrations aside from where Kubernetes gives a reflection, e.g., load balancer and capacity.
- Kubernetes can run on-premises exposed metal, OpenStack, Azure, public clouds Google, AWS, and so on.
- It will empower applications which should be delivered and refreshed with no vacation.
- Kubernetes permits you to guarantee those containerized applications operate where and when you need and assist you with discovering assets and apparatuses which you need to work.
# What is the function of clusters in Kubernetes?
Kubernetes permits you to authorize the necessary state management by taking care of cluster services of a particular setup. At that point, these cluster administrations operate that configuration in the foundation. The accompanying steps are associated with the method: The deployment document includes all the setups to be taken care of into the cluster administrations. The deployment document is taken care of into the API. Presently, the cluster services plan the pods in the climate. Cluster benefits likewise guarantee that the correct number of pods are operating. Along these lines, the Kubernetes cluster is basically composed of the API, the worker nodes, and the Kubelet cycle of the nodes.
# Characteristics of Kubernetes?
The characteristics of Kubernetes are:
- Self-Healing Capabilities
- Automated Scheduling
- Application-centric management
- You could make predictable infrastructure
- Automated rollouts & rollback
- Offers a higher density of resource utilization
- Horizontal Scaling & Load Balancing
- Provides enterprise-ready features
- Auto-scalable infrastructure
- Provides environment consistency for testing, development, and production.
- Infrastructure is lightly coupled to each segment and can act as a separate unit.
# Define Ingress network
Ingress network is an assortment of rules which goes about as a section highlighting the Kubernetes cluster. This permits inbound associations that can be arranged to give benefits remotely through load balance traffic, reachable URLs, or by providing name-based virtual facilitating. In this way, Ingress is an API object which oversees outer admittance to the services in a cluster, generally by HTTP, and is the most remarkable method of uncovering administration.
# List the uses of GKE
GKE (Google Kubernetes Engine) uses are given below:
It very well may be utilized to make docker container clusters
Resize application regulators
Update and redesign the clusters of container
Investigate clusters of the container.
GKE can be utilized to make a replication regulator, occupations, load balancer, administrations, container pods
# Explain the main components of Kubernetes architecture?
The two primary components include the master node and the worker node. Each of its components has individual components in them. The two segments have numerous in-fabricated administrations inside them. For instance, the master part has the kube-scheduler, kube-controller-manager, etcd, and kube-apiserver. The worker node has administrations like kubelet, container runtime, and kube-proxy functioning on every node.
# How do we control the resource usage of POD?
With the use of limit and request resource usage of a POD can be controlled.
Request: The number of resources being requested for a container. If a container exceeds its request for resources, it can be throttled back down to its request.
Limit: An upper cap on the resources a single container can use. If it tries to exceed this predefined limit it can be terminated if K8’s decides that another container needs these resources. If you are sensitive towards pod restarts, it makes sense to have the sum of all container resource limits equal to or less than the total resource capacity for your cluster.
# What are the various K8s services running on nodes and describe the role of each service?
Mainly K8 cluster consists of two types of nodes, executor and master.
Executor node: (This runs on slave node)
- Kube-proxy: This service is responsible for the communication of pods within the cluster and to the outside network, which runs on every node. This service is responsible to maintain network protocols when your pod establishes a network communication.
- kubelet: Each node has a running kubelet service that updates the running node accordingly with the configuration(YAML or JSON) file. NOTE: kubelet service is only for containers created by Kubernetes.
Master services:
- Kube-apiserver: Master API service which acts as an entry point to K8 cluster.
- Kube-scheduler: Schedule PODs according to available resources on executor nodes.
- Kube-controller-manager: is a control loop that watches the shared state of the cluster through the apiserver and makes changes attempting to move the current state towards the desired stable state
# What is PDB (Pod Disruption Budget)?
A Kubernetes administrator can create a deployment of a kind: PodDisruptionBudget for high availability of the application, it makes sure that the minimum number is running pods are respected as mentioned by the attribute minAvailable spec file. This is useful while performing a drain where the drain will halt until the PDB is respected to ensure the High Availability(HA) of the application. The following spec file also shows minAvailable as 2 which implies the minimum number of an available pod (even after the election).
# What are the various things that can be done to increase Kubernetes security?
By default, POD can communicate with any other POD, we can set up network policies to limit this communication between the PODs.
- RBAC (Role-based access control) to narrow down the permissions.
- Use namespaces to establish security boundaries.
- Set the admission control policies to avoid running the privileged containers.
- Turn on audit logging.
# How to monitor the Kubernetes cluster?
Prometheus is used for Kubernetes cluster monitoring. The Prometheus ecosystem consists of multiple components.
- Mainly Prometheus server which scrapes and stores time-series data.
- Client libraries for instrumenting application code.
- Push gateway for supporting short-lived jobs.
- Special-purpose exporters for services like StatsD, HAProxy, Graphite, etc.
- An alert manager to handle alerts on various support tools.
# How to get the central logs from POD?
This architecture depends upon the application and many other factors. Following are the common logging patterns
- Node level logging agent.
- Streaming sidecar container.
- Sidecar container with the logging agent.
- Export logs directly from the application.
# How to turn the service defined below in the spec into an external one?
Adding type: LoadBalancer and nodePort as follows:
1 | |
# How to configure TLS with Ingress?
Add tls and secretName entries.
1 | |
# What is a Kubernetes Operator?
Operators are software extensions to K8s which make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop.
# Why do we need Operators?
The process of managing applications in Kubernetes isn’t as straightforward as managing stateless applications, where reaching the desired status and upgrades are both handled the same way for every replica. In stateful applications, upgrading each replica might require different handling due to the stateful nature of the app, each replica might be in a different status. As a result, we often need a human operator to manage stateful applications. Kubernetes Operator is supposed to assist with this.
This will also help with automating a standard process on multiple Kubernetes clusters.
# What difference do you find between Docker Swarm and Kubernetes?
| Parameters | Kubernetes | Docker Swarm |
|---|---|---|
| GUI | Kubernetes Dashboard is the GUI | Has no GUI |
| Installation & cluster configuration | Setups are quite complicated but the cluster is robust. | Setup is easy but the cluster is not robust. |
| Auto-scaling | Can do auto-scaling. | Cannot do auto-scaling. |
| Scalability | Scales fast. | Scales 5 times faster than Kubernetes. |
| Load Balancing | Manual support needed for load balancing traffic between containers & pods. | Does auto load balancing of traffic between containers in clusters. |
| Data volumes | Can only share storage volumes with containers in the same pod. | Can share storage volumes with other containers. |
| Rolling updates and rollbacks | Does rolling updates and automatic rollbacks. | Can do rolling updates but no automatic rollbacks. |
| Logging and monitoring | Has in-built tools to perform logging and monitoring. | Requires 3rd party tools like ELK stack to do logging and monitoring. |
# What difference do you find between deploying applications on the host and containers?
When you deploy the application on hosts:
- There will be an operating system and that operating system will have a kernel which again will have diverse libraries (installed on the operating system) that are required for the application.
- In this kind of framework, you can have several applications and you will see all the applications sharing the libraries present in the operating system.
When you deploy an application on the container:
- In this architecture, you will have a kernel which will be the only common thing between all the applications.
- Here you will see every application has their necessary libraries and binaries isolated from the rest of the system, which cannot be approached by any other application.
- Like if one app needs access to Python, that particular app will get it, if the particular application needs access to Java, then only that particular app will have access to Java.
# What is Minikube?
Minikube is a tool used for easy running Kubernetes locally, it runs a single-code Kubernetes cluster within a virtual machine.
# How Kubernetes simplifies the containerized Deployment
A cluster of containers of applications running across multiple hosts requires communications. To make the communication happen, we require something that can scale, balance, and monitor the containers. As Kubernetes is an anti-agnostic tool that can run on any public to a private provider, it is the best choice that can simplify the containerized deployment.
# What is the role of Kube-apiserver and Kube-scheduler?
Kube-Apiserver:
- It follows the scale-out architecture & is the front-end of the master node control panel.
- Exposes all the APIs of the Kubernetes Master node components and establishes communication between the Kubernetes Node and the Kubernetes master components.
Kube-scheduler:
- It does distribution and management of workload on the worker nodes.
- It opts the most suitable node to run the unscheduled pod (based on resource requirements) & keeps a track on the resource utilization.
- It makes sure that no workload is scheduled on already full nodes.
# How do master nodes in Kubernetes work?
- Kubernetes master controls the nodes, and nodes have the containers in it.
- The individual containers are contained inside the pods and each pod can contain various numbers of containers based on the requirements & configuration.
- So when pods have to be deployed, they have to be deployed either using the interface or CLI (command line interface).
- These pods are scheduled on the nodes and on the basis of resource requirements, the pods are allocated to these nodes.
- Kube-apiserver (which is master node services) ensures that there is a communication between the Kubernetes node and master components.
# What are the different types of services in Kubernetes?
There are four types of services in Kubernetes:
- Cluster IP - Kubernetes Service is an abstraction defining a logical set of Pods running somewhere in your cluster, all providing the same functionality. When created, each Service is given a unique IP address which is also called clusterIP.
- Node Port - A NodePort is an open port that is on every node of your cluster. Kubernetes routes incoming traffic transparently on the NodePort to your service, even if the application is running on a different node.
- Load Balancer - It exposes the service externally using the load balancer of the cloud provider. Services to which the load balancer will route are automatically created.
- External name - It exposes the Service by using an arbitrary name (specified by ExternalName in the spec) by returning a CNAME record with its value.
# What do you understand about Cloud controller managers?
Cloud Controller Manager has to ensure consistent storage, abstract the cloud-specific code from the Kubernetes specific code, network routing, and manage the communication with the cloud services.
All these can be split into different containers (it depends on which cloud platform you are using) and this further allows the Kubernetes and cloud vendors code to get developed without creating any inter-dependency. So, the cloud vendor develops its code and connects with the cloud-controller-manager while running the Kubernetes.
There are 4 types of cloud controller managers:
- Node controller - Ensures that the node is deleted as soon it is stopped.
- Volume controller - Manages the storage and interacts with the cloud provider to orchestrate volume.
- Route Controller - Manages traffic routes in the underlying cloud infrastructures.
- Service Controller - It ensures the management of cloud provider load balancers.
# What is the difference between a replica set and a replication controller?
Both replica set and replication controller ensure that the given number of pod replicas are running at a given time. But the only point of difference between them is, replica leverages set-based selectors, while the replication controller uses equity-based controllers.
Selector-based Selectors:
It filters the keys according to a set of values. The selector based selector locks for pods whose label is mentioned in the set.
Equity-Based Selectors:
It filters by both label keys and values. The equity-based selector looks for the pods that have the exact phrase as mentioned in the label.
# What are federated clusters?
The Multiple Kubernetes clusters can be controlled/managed as a single cluster with the help of federated clusters. You can generate multiple Kubernetes clusters within a data center/cloud and use federation clusters to control/manage all of them in one place.
The federated clusters can achieve this by doing the following two things.
- Cross cluster discovery - Provides the ability to have DNS and Load Balancer with backends from all participating clusters.
- Sync Resources across clusters - Syncs resources across the clusters for deploying the same deployment set across multiple clusters.
# hat are the best security measures that you can take while using Kubernetes?
Here are a few ways to ensure security while using Kubernetes:
- By restricting access to ETCD
- By applying security updates to the environment regularly
- By implementing network segmentation
- By logging everything on the producing environment
- By having continuous security vulnerability scanning
- By having a strict policy or protocol for resources
- By enabling auditing
- By defining resource quota
- By limiting direct access to Kubernetes nodes
- By using images from the authorized repository only
# What are the main differences between the Docker Swarm and Kubernetes?
Docker Swarm is Docker’s native, open-source container orchestration platform that is used to cluster and schedule Docker containers. Swarm differs from Kubernetes in the following ways:
- Docker Swarm is more convenient to set up but doesn’t have a robust cluster, while Kubernetes is more complicated to set up but the benefit of having the assurance of a robust cluster
- Docker Swarm can’t do auto-scaling (as can Kubernetes); however, Docker scaling is five times faster than Kubernetes
- Docker Swarm doesn’t have a GUI; Kubernetes has a GUI in the form of a dashboard
- Docker Swarm does automatic load balancing of traffic between containers in a cluster, while Kubernetes requires manual intervention for load balancing such traffic
- Docker requires third-party tools like ELK stack for logging and monitoring, while Kubernetes has integrated tools for the same Docker Swarm can share storage volumes with any container easily, while Kubernetes can only share storage volumes with containers in the same pod
- Docker can deploy rolling updates but can’t deploy automatic rollbacks; Kubernetes can deploy rolling updates as well as automatic rollbacks
# What are the types of secrets available in Kubernetes?
Kubernetes provides several builtin types for some common usage scenarios. These types vary in terms of the validations performed and the constraints Kubernetes imposes on them.
| Builtin Type | Usage |
|---|---|
| Opaque | arbitrary user-defined data |
| kubernetes.io/service-account-token | service account token |
| kubernetes.io/dockercfg | serialized ~/.dockercfg file |
| kubernetes.io/dockerconfigjson | serialized ~/.docker/config.json file |
| kubernetes.io/basic-auth | credentials for basic authentication |
| kubernetes.io/ssh-auth | credentials for SSH authentication |
| kubernetes.io/tls | data for a TLS client or server |
| bootstrap.kubernetes.io/token | bootstrap token data |
# How to use secrets in Kubernetes?
Secrets can be defined as Kubernetes objects used to store sensitive data such as user name and passwords with encryption.
1 | |
# How to Create and Use ConfigMap with Kubernetes?
A Kubernetes ConfigMap is an API object that allows you to store data as key-value pairs. Kubernetes pods can use ConfigMaps as configuration files, environment variables or command-line arguments.
ConfigMaps allow you to decouple environment-specific configurations from containers to make applications portable. However, they are not suitable for confidential data storage.
# What is a Kubernetes StatefulSet?
StatefulSet[6] is the workload API object used to manage stateful applications. Manages the deployment and scaling of a set of Pods, and provides guarantees about the ordering and uniqueness of these Pods.
Like a Deployment, a StatefulSet manages Pods that are based on an identical container spec. Unlike a Deployment, a StatefulSet maintains a sticky identity for each of their Pods. These pods are created from the same spec, but are not interchangeable: each has a persistent identifier that it maintains across any rescheduling.
Using StatefulSets:
StatefulSets are valuable for applications that require one or more of the following.
- Stable, unique network identifiers.
- Stable, persistent storage.
- Ordered, graceful deployment and scaling.
- Ordered, automated rolling updates.
Example: The example below demonstrates the components of a StatefulSet.
1 | |
# What are levels of abstraction in Kubernetes?
Deployments create and manage ReplicaSets, which create and manage Pods, which run on Nodes, which have a container runtime, which run the app code you put in your Docker image.
Here are the six layers of abstractions when running a workload in Kubernetes starting with the highest-level abstraction.
- Deployment
- ReplicaSet
- Pod
- Node Cluster
- Node Processes
- Docker Container
# How to Configure Kubernetes for Rolling Update?
One of the primary benefits of using a Deployment to control your pods is the ability to perform rolling updates. Rolling updates allow you to update the configuration of your pods gradually, and Deployments offer many options to control this process.
The deployment file properly configured for rolling updates should look like this:
1 | |
- initialDelaySeconds specifies how long the probe has to wait to start after the container starts.
- periodSeconds is the time between two probes. The default is 10 seconds, while the minimal value is 1 second.
- successThreshold is the minimum number of consecutive successful probes after a failed one for the entire process to be considered successful. The default and minimal values are both 1.
1 | |
There are three ways to perform rolling updates.
For example, to change the app image:
Option 1: You can use kubectl set to perform the action on the command line:
1 | |
Option 2: Alternatively, modify the image version in the spec.templates.spec.containers section of the yaml file. Then, use kubectl replace to perform the update:
1 | |
Option 3: You can also use kubectl edit to edit the deployment directly:
1 | |
# What is the difference between Docker Compose and Kubernetes?
Docker (or specifically, the docker command) is used to manage individual containers, docker-compose is used to manage multi-container applications and Kubernetes is a container orchestration tool.
Docker Compose:
- Docker Compose is the declarative version of the docker cli
- It can start one or more containers
- It can create one or more networks and attach containers to them
- It can create one or more volumes and configure containers to mount them
- All of this is for use on a single host
Kubernetes:
- Kubernetes is a platform for managing containerized workloads and services, that facilitates both declarative configuration and automation.
- are fault-tolerant,
- can scale, and do this on-demand
- use resources optimally
- can discover other applications automatically, and communicate with each other
- can update/rollback without any downtime.
# What is the difference between kubernetes load balancer and ingress controller?
Load balancer distributes the requests among multiple backend services (of same type) whereas ingress is more like an API gateway (reverse proxy) which routes the request to a specific backend service based on, for instance, the URL.
- A Kubernetes LoadBalancer is a type of Service.
- A Kubernetes Ingress is not a type of Service. It is a collection of rules. An Ingress Controller in your cluster watches for Ingress resources, and attempts to update the server side configuration according to the rules specified in the Ingress.
# When would you use a Deployment versus a StatefulSet versus a DaemonSet?
Deployments:
Deployment is the easiest and most used resource for deploying your application. It is a Kubernetes controller that matches the current state of your cluster to the desired state mentioned in the Deployment manifest.
StatefulSets:
StatefulSet(stable-GA in k8s v1.9) is a Kubernetes resource used to manage stateful applications. It manages the deployment and scaling of a set of Pods, and provides guarantee about the ordering and uniqueness of these Pods.
StatefulSet is also a Controller but unlike Deployments, it doesn’t create ReplicaSet rather itself creates the Pod with a unique naming convention.
DaemonSet:
A DaemonSet is a controller that ensures that the pod runs on all the nodes of the cluster. If a node is added/removed from a cluster, DaemonSet automatically adds/deletes the pod.
Some typical use cases of a DaemonSet is to run cluster level applications like:
- Monitoring Exporters
- Logs Collection Daemon
# What are container orchestrators and why are they required?
Container orchestration is all about managing the lifecycles of containers, especially in large, dynamic environments. Software teams use container orchestration to control and automate many tasks:
- Provisioning and deployment of containers
- Redundancy and availability of containers
- Scaling up or removing containers to spread application load evenly across host infrastructure
- Movement of containers from one host to another if there is a shortage of resources in a host, or if a host dies
- Allocation of resources between containers
- External exposure of services running in a container with the outside world
- Load balancing of service discovery between containers
- Health monitoring of containers and hosts
- Configuration of an application in relation to the containers running it
# What type of workloads run well on Kubernetes, and what types do not?
A workload is an application running on Kubernetes. Whether your workload is a single component or several that work together, on Kubernetes you run it inside a set of pods. In Kubernetes, a Pod represents a set of running containers on your cluster.
Kubernetes provides several built-in workload resources:
- Deployment and ReplicaSet (replacing the legacy resource ReplicationController). Deployment is a good fit for managing a stateless application workload on your cluster, where any Pod in the Deployment is interchangeable and can be replaced if needed.
- StatefulSet lets you run one or more related Pods that do track state somehow. For example, if your workload records data persistently, you can run a StatefulSet that matches each Pod with a PersistentVolume. Your code, running in the Pods for that StatefulSet, can replicate data to other Pods in the same StatefulSet to improve overall resilience.
- DaemonSet defines Pods that provide node-local facilities. These might be fundamental to the operation of your cluster, such as a networking helper tool, or be part of an add-on. Every time you add a node to your cluster that matches the specification in a DaemonSet, the control plane schedules a Pod for that DaemonSet onto the new node.
- Job and CronJob define tasks that run to completion and then stop. Jobs represent one-off tasks, whereas CronJobs recur according to a schedule.
# What is the Operator pattern and when should you use it?
Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop.
Kubernetes operator pattern concept lets you extend the cluster’s behaviour without modifying the code of Kubernetes itself by linking controllers to one or more custom resources. Operators are clients of the Kubernetes API that act as controllers for a Custom Resource.
Some of the things that you can use an operator to automate include:
- deploying an application on demand
- taking and restoring backups of that application’s state
- handling upgrades of the application code alongside related changes such as database schemas or extra configuration settings
- publishing a Service to applications that don’t support Kubernetes APIs to discover them
- simulating failure in all or part of your cluster to test its resilience
- choosing a leader for a distributed application without an internal member election process
# How can RBAC be used to grant permission to Kubernetes resources?
Role-based access control (RBAC) is a method of regulating access to computer or network resources based on the roles of individual users within your organization.
RBAC authorization uses the rbac.authorization.k8s.io API group to drive authorization decisions, allowing you to dynamically configure policies through the Kubernetes API.
To enable RBAC, start the API server with the --authorization-mode flag set to a comma-separated list that includes RBAC; for example:
1 | |
The RBAC API declares four kinds of Kubernetes object: Role, ClusterRole, RoleBinding and ClusterRoleBinding.
# What is Helm Charts?
Helm Charts are simply Kubernetes YAML manifests combined into a single package that can be advertised to your Kubernetes clusters. Once packaged, installing a Helm Chart into your cluster is as easy as running a single helm install, which really simplifies the deployment of containerized applications.
Helm has two parts to it:
- The client (CLI), which lives on your local workstation.
- The server (Tiller), which lives on the Kubernetes cluster to execute what’s needed.
# How to persist data in kubernetes using volumes?
Kubernetes Persistent Volumes are a type of Volume that lives within the Kubernetes cluster, and can outlive other Kubernetes pods to retain data for long periods of time.
Persistent volumes are independent of the lifecycle of the pod that uses it, meaning that even if the pod shuts down, the data in the volume is not erased. They are defined by an API object, which captures the implementation details of storage such as NFS file shares, or specific cloud storage systems.
Kubernetes provides an API to separate storage from computation, i.e., a pod can perform computations while the files in use are stored on a separate resource. The API introduces 2 types of resources:
- PersistentVolumes are used to define a storage volume in the system, but their lifecycle is independant of the ones of the pods that use them. PersistentVolumes are Volume plugins and the API supports a large variety of implementation, including NFS, Glusterfs, CephFS, as well as cloud-providers such as GCEPersistentDisk, AWSElasticBlockStore, AzureFile and AzureDisk, amongst others.
- PersistentVolumeClaims are requests emitted by pods to obtain a volume. Once obtained, the volume is mounted on a specific path in the pod, while providing an abstraction to the underlying storage system. A claim may specify a storageClassName attribute to obtain a PersistentVolume that satisfies the specific needs of the pod.
# How to create storage class in kubernetes?
A StorageClass provides a way for administrators to describe the “classes” of storage they offer. Each StorageClass contains the fields provisioner, parameters, and reclaimPolicy, which are used when a PersistentVolume belonging to the class needs to be dynamically provisioned.
Administrators set the name and other parameters of a class when first creating StorageClass objects, and the objects cannot be updated once they are created. Administrators can specify a default StorageClass only for PVCs that don’t request any particular class to bind to.
1 | |